
Consortium seeks to holistically address food recalls
The Department of Biosystems and Agricultural Engineering at Oklahoma State University (OSU BAE) is leading a multi-institutional, multi-disciplinary consortium in the preparation of funding applications for two significant coordinated agricultural projects. If successful, up to $25M for 5 years will be provided for each project beginning in 2011 under the USDA’s Agriculture & Food Research Initiative for Food Safety (CFDA Number - 10.310 - AFRI). Other institutions currently involved in this growing consortium include researchers and investigators from Michigan State University, North Dakota State University, University of Arkansas, Texas Tech University and the National Center for Food Protection and Defense, a DHS Center of Excellence. For the purposes of these activities, Pardalis Inc. is embedded within OSU BAE. The applications will be filed in September, 2010. More information can be found on this site at USDA AFRI Stakeholder Solicitations.
The vision of our consortium is to
- advance technologies for the prevention, detection, and control of foodborne microbes and viruses in agricultural and food products,
- manage coordinated agricultural projects with direct input from a stakeholder advisory workgroups, and
- improve upon real-time consumer responses to food safety recalls with innovative sensor, mobile and "whole chain" information traceability technologies.
The members of our consortium have been highly influenced in their thinking by the existing data showing that many consumers do not take appropriate protective actions during a foodborne illness outbreak or food recall. The Centers for Disease Control and Prevention estimates that every year at least 2000 Americans are hospitalized, and about 60 die as a direct result of E. coli infections. A recent study estimated the annual cost of E. coli O157:H7 illnesses to be $405M (in ‘03 dollars), which included $370M for premature deaths, $30M for medical care, and $5M for lost productivity. And that doesn’t include the costs of lost sales from consumers fearful of purchasing tainted meat due to the lack of real-time, reliable information.
Furthermore, 41 percent of U.S. consumers say they have never looked for any recalled product in their home. Conversely, some consumers overreact to the announcement of a foodborne illness outbreak or food recall. In response to the 2006 fresh, bagged spinach recall which followed a multistate outbreak of Escherichia coli O157: H7 infections, 18 percent of consumers said they stopped buying other bagged, fresh produce because of the spinach recall.
We envision the model implementation of a "whole chain" product traceability system (call it a "Food Recall Data Bank") to help solve the serious cry wolf problem experienced by consumers. The Food Recall Data Bank model would place a premium on privacy and loyalty. It would provide granular recall notices to pre-retailers, retailers and consumers. Each would centrally populate their accounts in the Food Recall Data Bank with GTIN or UPC product identifiers of relevance to their operations or consumption habits. 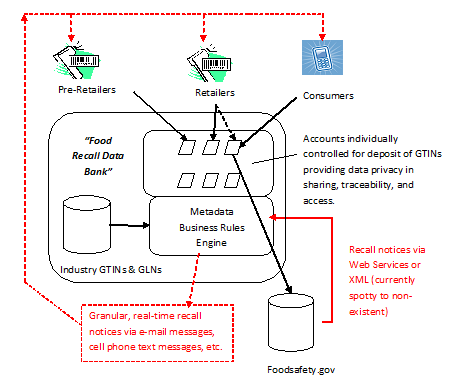
For instance, consumers could opt for retailers to automatically populate their accounts from their actual POS retail purchases. Consumers could additionally populate accounts using mobile image capturing applications (e.g., Microsoft Tag Mobile Barcode app). Supplemented by cross-reference to an Industry GTIN/GLN database, the product identifiers would be associated with company names, time stamps, location and similar metadata. Consumers would also be provided with a one-stop shop for confidentially reporting suspicious food to Recalls.gov.
This consortium is only just getting started. Other funding opportunities are being targeted. Let’s talk if you have a commercial or research interest in:
- the effects of financial damages suffered by enterprises - directly or indirectly - from food safety recalls,
- mining and analyzing the real-time data of agricultural product supply chains - including the real-time data of consumers purchasing habits, or
- the applicability of these issues to non-agricultural product supply chains.
 Steve Holcombe
Steve Holcombe
The consortium identified above is now known as the Whole Chain Traceability Consortium™. The WCTC is comprised at its core of researchers and collaborators from Oklahoma State University, North Dakota State University, Michigan State University, the University of Arkansas, and Pardalis, Inc., an Oklahoma advanced technology company. Whole Chain Traceability Consortium™ is a trademark of Pardalis, Inc. For more information, see http://pardalis.squarespace.com/blog/2011/10/29/the-whole-chain-traceability-consortium.html
;)
