The Tipping Point Has Arrived: Market Incentives for Selective Sharing in Web Communications
By Steve Holcombe (@steve_holcombe) and Clive Boulton (@iC)
A Glimmer of Market Validation for Selective Sharing
In late 2005 Pardalis deployed a multi-tenant, enterprise-class SaaS to a Texas livestock market. The web-connected service provided for the selective sharing of data assets in the U.S. beef livestock supply chain. Promising revenues were generated from a backdrop of industry incentives being provided for sourced livestock. The industry incentives themselves were driven by the specter of mandatory livestock identification promised by the USDA in the wake of the 2003 "mad cow" case.
 At the livestock market thousands of calves were processed over several sessions. Small livestock producers brought their calves into the auction for weekly sales where they were RFID tagged. An affordable fee per calf was charged to the producers which included the cost of a RFID tag. The tags identifiers were automatically captured, a seller code was entered, and affidavit information was also entered as to the country of origin (USA) of each calf. Buyers paid premium prices for the tagged calves over and above untagged calves. The buyers made money over and above the affordable fee per calf. After each sale, and at the speed of commerce, all seller, buyer and sales information was uploaded into an information tenancy in the SaaS that was controlled by the livestock market. For the first time ever in the industry, the livestock auction selectively authorized access to this information to the buyers via their own individual tenancies in the SaaS.
At the livestock market thousands of calves were processed over several sessions. Small livestock producers brought their calves into the auction for weekly sales where they were RFID tagged. An affordable fee per calf was charged to the producers which included the cost of a RFID tag. The tags identifiers were automatically captured, a seller code was entered, and affidavit information was also entered as to the country of origin (USA) of each calf. Buyers paid premium prices for the tagged calves over and above untagged calves. The buyers made money over and above the affordable fee per calf. After each sale, and at the speed of commerce, all seller, buyer and sales information was uploaded into an information tenancy in the SaaS that was controlled by the livestock market. For the first time ever in the industry, the livestock auction selectively authorized access to this information to the buyers via their own individual tenancies in the SaaS.
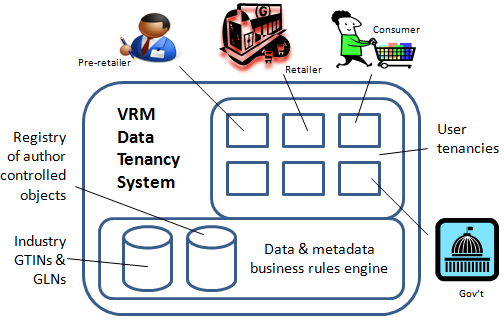
That any calves were processed at all was not possible without directly addressing the fear of information sharing that was held by both the calf sellers and the livestock market. The calf sellers liked that their respective identities were selectively withheld from the calf buyers. And they liked that a commercial entity they trusted – the livestock market – could stand as a kind of trustee between them and governmental regulators in case an auctioned calf later turned out to be the next ‘mad cow’. In turn the livestock market liked the selectiveness in information sharing because it did not have to share its confidential client list in an “all or nothing” manner to potential competitors on down the supply chain. At that moment in time, the immediate future of selective sharing with the SaaS looked very bright. The selective sharing design deployed by Pardalis in its SaaS fixed data elements at a single location with authorizations controlled by the tenants. Unfortunately, the model could not be continued and scaled at that time to other livestock markets. In 2006 the USDA bowed to political realities and terminated its efforts to introduce national mandatory livestock identification.
And so, too, went the regulatory-driven industry incentives. But … hold that thought.
Talking in Circles: Selective Sharing in Google+
Google+ is now 1 year old. In conjunction with Google, researchers Sanjay Kairam, Michael J. Brzozowski, David Huffaker, and Ed H. Chi have published Talking in Circles: Selective Sharing in Google+, the first empirical study of behavior in a network designed to facilitate selective sharing:
"Online social networks have become indispensable tools for information sharing, but existing ‘all-or-nothing’ models for sharing have made it difficult for users to target information to specific parts of their networks. In this paper, we study Google+, which enables users to selectively share content with specific ‘Circles’ of people. Through a combination of log analysis with surveys and interviews, we investigate how active users organize and select audiences for shared content. We find that these users frequently engaged in selective sharing, creating circles to manage content across particular life facets, ties of varying strength, and interest-based groups. Motivations to share spanned personal and informational reasons, and users frequently weighed ‘limiting’ factors (e.g. privacy, relevance, and social norms) against the desire to reach a large audience. Our work identifies implications for the design of selective sharing mechanisms in social networks."
While selective sharing may be characterized as being available on other networks (e.g. ‘Lists’ on Facebook), Google is sending signals that making the design of selective sharing controls central to the sharing model offers a great opportunity to help users manage their self-presentations to multiple audiences in the multi-tenancies we call online social networks. Or, put more simply, selective sharing multiplies opportunities for online engagement.
For the purposes of this blog post, we adopt Google’s definition of "selective sharing" to mean providing information producers with controls for overcoming both over-sharing and fear of sharing. Furthermore, we agree with Google that that the design of tools for such selective sharing controls must allow users to balance sender and receiver needs, and to adapt these controls to different types of content. So defined, we believe that almost seven years since the Texas livestock market project, a tipping point has been reached that militates in favor of selective sharing from within supply chains and on to consumers. Now, there have been a lot of things happen over the last seven years that bring us to this point (e.g., the rise of social media, CRM in the Cloud, the explosion of mobile technologies, etc.). But the tipping point we are referencing "follows the money", as they say. We believe that the tipping point toward selective sharing is to be found in the incentives provided by affiliate networks like Google Affiliate Networks.
Google Affiliate Networks
Google Affiliate networks provide a means for affiliates to monetize websites. Here’s a recent video presentation by Google, Automating the Use of Google Affiliate Links to Monetize Your Web Site:
Presented by Ali Pasha & Shaun Cox | Published 2 July 2012 | 47m 11s
The Google Affiliate Network provides incentives for affiliates to monetize their websites based upon actual sales conversions instead of indirectly based upon the number of ad clicks. These are web sites (e.g., http://www.savings.com/) where ads are the raison d'etre of the web site. High value consumers are increasingly scouring promotional, comparison, and customer loyalty sites like savings.com for deals and generally more information about products. Compare that with websites where ads are peripheral to other content (e.g., http://www.nytimes.com/) and where ad clicks are measured using Web 2.0 identity and privacy sharing models.
In our opinion the incentives of affiliate networks have huge potential for matching up with an unmet need in the Cloud for all participants - large and small - of enterprise supply chains to selectively monetize their data assets. For example, data assets pertaining to product traceability, source, sustainability, identity, authenticity, process verification and even compliance with human rights laws, among others, are there to be monetized.
Want to avoid buying blood diamonds? Go to a website that promotes human rights and click on a diamond product link that has been approved by that site. Want to purchase only “Made in USA” products? There’s not a chamber of commerce in the U.S. that won’t want to provide a link to their members’ websites who are also affiliates of an incentive network. Etc.
Unfortunately, these data assets are commonly not shared because of the complete lack of tools for selective sharing, and the fear of sharing (or understandable apathy) engendered under “all or nothing” sharing models. As published back in 1993 by the MIT Sloan School in Why Not One Big Database? Ownership Principles for Database Design: "When it is impossible to provide an explicit contract that rewards those who create and maintain data, ‘ownership’ will be the best way to provide incentives." Data ownership matters. And selective sharing – appropriately designed for enterprises – will match data ownership up with available incentives.
Remember that thought we asked you to hold?
In our opinion the Google Affiliate Network is already providing incentives that are a sustainable, market-driven substitute for what turned out to be unsustainable, USDA-driven incentives. We presume that Google is well aware of potential synergies between Google+ and the Google Affiliate Network. We also presume that Google is well aware that "[w]hile business-critical information is often already gathered in integrated information systems, such as ERP, CRM and SCM systems, the integration of these systems itself (as well as the integration with the abundance of other information sources) is still a major challenge."
We know this is a "big idea" but in our opinion the dynamic blending of Google+ and the Google Affiliate Network could over time bring within reach a holy grail in web communications – the cracking of the data silos of enterprise class supply chains for increased sharing with consumers of what to-date has been "off limits" proprietary product information.
A glimpse of the future may be found for example in the adoption of Google+ by Cadbury UK, but the design for selective sharing of Google+ is currently far from what it needs to attract broad enterprise usage. Sharing in Circles brings to mind Eve Maler’s blog post, Venn and the Art of Data Sharing. That’s really cool for personal sharing (or empowering consumers as is the intent of VRM) but for enterprises Google+ will need to evolve its selective sharing functionalities. Sure, data silos of commercial supply chains are holding personal identities close to their chest (e.g., CRM customer lists) but they’re also walling off product identities with every bit as much zeal, if not more. That creates a different dynamic that, again, typical Web 2.0 "all or nothing" sharing (designed, by the way, around personal identities) does not address.
It should be specially noted, however, that Eve Maler and the User-Managed Access (UMA) group at the Kantara Initiative are providing selective sharing web protocols that place "the emphasis on user visibility into and control over access by others". And Eve in her capacity at Forrester has more recently provided a wonderful update of her earlier blog post, this one entitled A New Venn of Access Control for the API Economy.
But in our opinion before Google+, UMA or any other companies or groups working on selective sharing can have any reasonable chance of addressing "data ownership" in enterprises and their supply chains, they will need to take a careful look at incorporating fixed data elements at a single location with authorizations. It is in regard to this point that we seek to augment the current status of selective sharing. More about that line of thinking (and activities within the WikiData Project) in our earlier “tipping point” blog post, The Tipping Has Arrived: Trust and Provenance in Web Communications.
What do you think? Share your conclusions and opinions by joining us at @WholeChainCom on LinkedIn at http://tinyurl.com/WholeChainCom.
 Steve Holcombe
Steve Holcombe
@NZN: @Steve_Holcombe well-stated.I'd like more on undrlined element,last paragraph:"fixed data elements at a single location with authorizations"
@Steve_Holcombe: @NZN Foundational #OO design - http://tinyurl.com/76a4jtm | Livestock project model - http://tinyurl.com/7sb9x37 | Also see #Wikidata project.
Steve Holcombe
Coincidentally, see:
WebCollage Takes Ad Copy Mobile for Top Retailers
[WebCollage posts consistent ad copy on multiple retailers’ sites]
Arlene Weintraub | 7/16/12 | Xconomy.com
http://www.xconomy.com/new-york/2012/07/16/webcollage-takes-ad-copy-mobile-for-top-retailers/
About Pardalis, Agriculture, Business Models, Cloud Computing, Economic modeling, First Movers, Granularity, Identity, Informational Objects, Ownership, RFID, SaaS, Semantic Trust, Social Networking, Standards, Supply Chains, Sustainability, Traceability, User-centric, VRM, Whole Chain, XML