
The Roots of Common Point Authoring (CPA)
Common Point Authoring (CPA) is timely and relevant for amerliorating the fear factors revolving around data ownership. Those fears are multiplying from the every increasing usage of unique identification on the Internet as applied to both people (e.g., social security numbers) and products (e.g., unique electronic product numbers and RFID tags).
Q&A: What is an informational object?
Consider the electronic form of this document (the one you are reading right now) as an example of a informational object. Imagine that you are the author and owner of this informational object. Imagine that each paragraph of this object has a granular on/off switch that you control. Imagine being able to granularly control who sees which paragraph even as your informational object is electronically shared one-step, two-steps, three-steps, etc., down a supply chain with people or businesses you have never even heard of. Now further imagine being able to control the access to individual data elements within each of those paragraphs.
The methods for CPA were first envisioned in regards to transforming the authoring of paper-based material safety data sheets (MSDSs) in the chemical industry into a market-driven, electronic service provided by chemical manufacturers for their supply chain customers. You may think of MSDSs as a type of chemical pedigree document authored by chemical manufacturers and then handed down a multi-party supply chain as it follows the trading of the chemical.
At the time, we crunched some numbers and found that MSDSs offered as a globally accessible software service could be provided to downstream users for significantly less than what it cost them to handle paper MSDSs. But we further recognized that our business model for global software services wouldn’t work very well unless the fear factors revolving around MSDSs offered as a service were technologically addressed.
That is, we asked the question, “How can electronic information be granularly controlled by the original author (i.e., creator) as it is shared down a supply chain?”
When it comes to information sharing in multi-tenancies, the prior art (i.e., the prior patents and other published materials) to CPA at best refers to collaborative document editing systems where multiple parties share in the authoring of a single document. A good example of the prior art is found in a 1993 Xerox patent entitled 'Updating local copy of shared data in a collaborative system' (US Patent 5,220,657 - Xerox) covering:
“A multi-user collaborative system in which the contents as well as the current status of other user activity of a shared structured data object representing one or more related structured data objects in the form of data entries can be concurrently accessed by different users respectively at different workstations connected to a common link.”
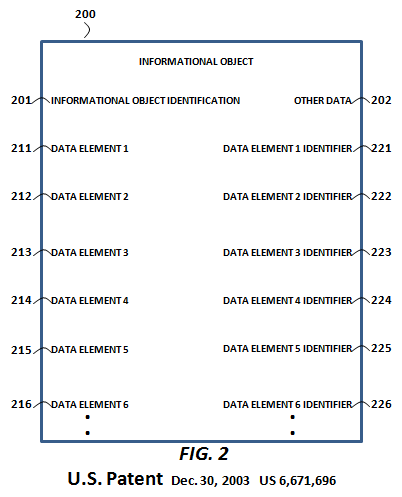 By contrast, CPA's methods provide for the selective sharing of informational objects (and their respective data elements) without the necessity of any collaboration. More specifically, CPA provides the foundational methods for the creation and versioning of immutable data elements at a single location by an end-user (or a machine). Those data elements are accessible, linkable and otherwise usable with meta-data authorizations. This is especially important when it comes to overcoming the fear factors to the sharing of enterprise data, or allowing for the semantic search of enterprise data. To the right is a representation from Pardalis' parent patent, "Informational object authoring and distribution system" (US Patent 6,671,696), of a granular, author-controlled, structured informational object around which CPA's methods revolve.
By contrast, CPA's methods provide for the selective sharing of informational objects (and their respective data elements) without the necessity of any collaboration. More specifically, CPA provides the foundational methods for the creation and versioning of immutable data elements at a single location by an end-user (or a machine). Those data elements are accessible, linkable and otherwise usable with meta-data authorizations. This is especially important when it comes to overcoming the fear factors to the sharing of enterprise data, or allowing for the semantic search of enterprise data. To the right is a representation from Pardalis' parent patent, "Informational object authoring and distribution system" (US Patent 6,671,696), of a granular, author-controlled, structured informational object around which CPA's methods revolve.
When it comes to "electronic rights and transaction management", CPA's methods have further been distinguished from a significant patent held by Intertrust Technologies. See Methods for matching, selecting, narrowcasting, and/or classifying based on rights management and/or other information (US Patent 7,092,914 - Intertrust Technologies). By the way, in a 2004 announcement Microsoft Corp. agreed to take a comprehensive license to InterTrust's patent portfolio for a one-time payment of $440 million.
CPA's methods have been further distinguished worldwide from object-oriented, runtime efficiency IP held by these leaders in back-end, enterprise application integration: Method and system for network marshalling of interface pointers for remote procedure calls (US Patent 5,511,197 - Microsoft), Reuse of immutable objects during object creation (US Patent 6,438,560 - IBM), Method and software for processing data objects in business applications (US Patent 7,225,302 - SAP), and Method and system to protect electronic data objects from unauthorized access (US Patent 7,761,382 - Siemens).
For more information, see Pardalis' Global IP.
 Steve Holcombe
Steve Holcombe