Whole Chain Traceability: A Successful Research Funding Strategy - Part II
Preface
I published Part I in January 2012. Since then Oklahoma State University has announced that funding has been provided toward the formation of a National Institute for Whole Chain Traceability and Food Safety. The principal investigators are Dr. Michael Buser, Biosystems & Agricultural Engineering and Dr. Brian Adam, Agricultural Economics. This post is to correct an omission in attribution to work product provided by Pardalis Inc. which was has played (and apparently continues to play) a critical role in OSU's intended formation of the National Institute.
A Handshake Agreement
In late 2009 I approached Oklahoma State University (OSU) researchers. We (that is, the OSU researchers and Pardalis) verbally agreed to go after governmental and private "food traceability" funding which would be used to employ Pardalis' database system - engineered from Pardalis’ patents - by OSU.[1] That database system was physically taken into possession by OSU behind their firewall in January 2010. Concurrently, Pardalis introduced OSU researchers to its informal “traceability consortium” of researchers at North Dakota State University and Michigan State University, and to John Bailey at Top 10 Produce LLC, Salinas, California. Together these institutions and companies submitted a $4 million (for use over a projected 5 years) application under the USDA NIFA Specialty Crops Research Initiative (SCRI) for a coordinated agricultural project entitled A Real–Time, Item Level, Stakeholder Driven Traceability System for Fresh Produce. My work product contribution (i.e., Pardalis’ contribution) for this first funding submission is found in Objective 2: Development of a Data Repository Traceability System.[2] That work product includes a high-level, diagrammatic comparison of the product traceability initiative's one-up, one down approach to information sharing with an approach more akin to the sharing of information found within social media (using Pardalis' database system).
Prior work product of Pardalis’ that was drawn upon by me for developing Objective 2 may be found in Laying the First Plank of a Supply Chain Ownership Web in North Dakota (September 2008), International Symposium on Certification and Traceability for Food Safety and Quality (Oct 2007), Banking on Granular Information Ownership (April 2007) and A New Information Marketplace for the Beef Industry (March 2004).
While we were waiting to hear back on the SCRI submission the opportunity to file for Oklahoma EDGE Funding arose. But what to apply for? I proposed that we assume that the SCRI funding would be successful, and that we seek additional funds for establishing a product center from the Oklahoma EDGE Fund submission. We did that and the $3.1M submission (co-authored and co-signed by me) was entitled Leveraging USDA Specialty Crops Funding to Lay the First Foundational (sic) of a Conceptual OSU Agricultural Product Traceability Center.
"The investment of EDGE funds is not necessary for the long-term success of the Pardalis/OSU collaboration; it will accelerate the success. When it comes to information technology, Oklahoma is universally regarded as a "fly-over" state. The investment of EDGE funds are essential in providing Oklahoma with the best opportunity to (a) rapidly expand the number of researchers, technicians, and support services in the area of food safety within the State of Oklahoma, (b) rapidly grow an existing, home-grown advanced technology company in Oklahoma [i.e., Pardalis Inc.], and (c) accelerate the development and deployment of an Agricultural Product Traceability Center at OSU that will be well positioned to attract $100s of millions in federal research grants and/or privately funded research."
Neither the SCRI submission nor the Oklahoma EDGE submission were successful. No reviewers' comments of any value were provided by the EDGE fund. But the USDA’s reviewers’ comments were valuable:
"The proposed project addresses a major concern of the produce industry, traceability of fresh produce. The project focuses on traceability at the item level, which is on the wish list of the industry. The proposal to explore social media systems could be used to trace items through complex supply chains .... The proposal needs to be heavily reorganized and a clear, well defined plan for the proposed research developed."[3]
Introducing and Defining "Whole Chain Traceability"
The failures of the prior funding submissions did not deter the OSU researchers and me. In the summer of 2010 we went after two significant USDA Agricultural and Food Research Initiative (AFRI) submissions, both providing an opportunity for funding of up to $25M over 5 years. This is where the contributions to the funding submissions made by me became more distinct and modular. "Food traceability" needed to be more clearly defined in our funding submissions to increase the chances of the success we had so far been missing. That's when I created and contributed new work product.[4] See Pardalis’ Facilities, Equipment and Resources letter that was attached to the AFRI STEC submission entitled Stakeholder-driven food supply safety system for a real-time detection, risk assessment, and mitigation of Shiga toxin-producing Escherichia coli [STEC] in beef products. In the letter you’ll find the work product where I for the first time introduced and defined "whole chain traceability" by extending the CTIDs envisioned by the IFT/FDA to the more granular CTIDs envisioned by Pardalis' patents. Here's an excerpt:
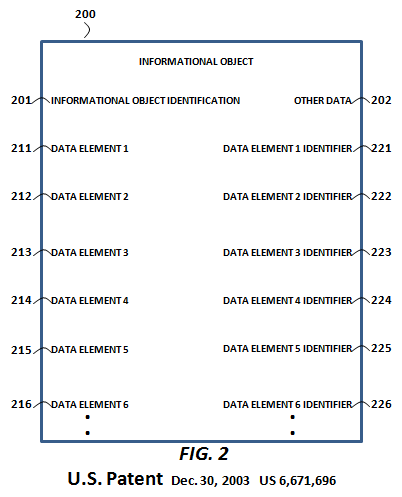
"A useful explanation of the benefits of a "whole chain" produce traceability system may be made with critical traceability identifiers (CTIDs), critical tracking events (CTEs) and Nodes.[5]. Critical tracking events (CTE) are those events that must be recorded in order to allow for effective traceability of products in the supply chain. A Node refers to a point in the supply chain when an item is produced, process, shipped or sold. CTE’s can be loosely defined as a transaction. Every transaction involves a process that can be separated into a beginning, middle and end.
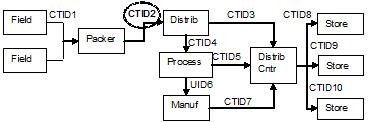
While important and relevant data may exist in any of the phases of a CTE transaction, the entire transaction may be uniquely identified and referenced by a code referred to as a critical tracking identifier (CTID). Now, with the emergence of biosensor development for the real-time detection of foodborne contamination, one may also envision adding associated real-time environmental sampling data from each node. The challenge is in using even top of the line "one up/one down" product traceability systems (compare CTID2 in the foregoing drawing with CTID2 in the next drawing) that, notwithstanding the use of a single CTID, are inherently limiting in the data sharing options provided to both stakeholders and government regulators. With the proposed stakeholder-driven "Whole Chain" product traceability system, in which CTID2 is essentially assigned down to the datum level, transactional and environmental sampling data may in real-time be granularly placed into the hands of supply chain partners, food safety regulators, or even retail customers.
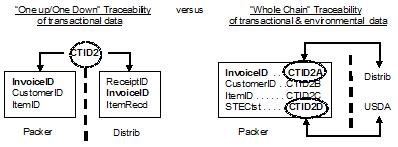
This is a vision of "whole chain" chain (sic) sharing that goes well beyond "one up/one down" information sharing, and recognizes the need for control or "data ownership" by each [of the] stakeholders."
A similar “facilities, equipment and resources” letter from Pardalis was attached to the AFRI Norovirus submission entitled Stakeholder driven food supply safety system for a real-time detection, risk assessment, and mitigation of [norovirus] food borne contamination. And the work product from both of these letters was clearly incorporated into the all important narrative for each AFRI submission, respectively. When you do your diligence, ask to see the content in each AFRI submission under Objective 5. Development of Stakeholder-driven Traceability System. In particular ask to see Phase 2 to Objective 5 entitled Technical development and deployment of “whole chain” product traceability system. Dr. Michael Buser has copies of those submissions as he was a lead principal investigator for all of the funding submissions beginning with the SCRI submission, above.
We filed the two AFRI submissions in August and September of 2010, respectively. We found out later (in 2011) that neither of these AFRI submissions would be successful. But we felt very strongly that we were on the right track. Consequently, in October 2010 this work product is also described in detail in my technology transfer proposal to Dr. Clarence Watson, then the Associate Director of the Oklahoma Agricultural Experiment Station, entitled Proposing a National Agricultural Product Traceability Center at Oklahoma State University.[6]
Pardalis' work product relative to "whole chain traceability" was also described in detail in The Bullwhip Effect series I authored and published beginning in January 2011.
The graphical representations describing whole chain traceability (or derivatives of them) are included in a series of presentations in 2011 (made with the full knowledge and participation of OSU researchers) to companies and institutions like Syngenta [presentation], the Oklahoma State Department of Health [presentation] (with a personal introduction by Senator James Halligan), Nestle’ (when I initiated contact with Dr. Sam Saguy), Gartner (when I initiated contact with Vladimir Krasojevic, then a supply chain Research Director), GS1 (when I initiated contact with Stephen Arens, then Director of Strategic Partnerships), the OSU Food and Agricultural Products Center [presentation] (at the invitation of Director Roy Escoubas), the Association of Overseas Chinese Agricultural, Biological, and Food Engineers [presentation], the EU-funded SmartAgriFood Project (when I made contact with Dr. Sjaak Wolfert), and others.
Pardalis' work product is again described in detail in an the internal OSU provost proposal submitted in June 2011 entitled A Content-Centric Food Traceability System. While the provost proposal was unsuccessful, it is essentially a "lite" version of the USDA NIFSI proposal successfully made (finally) as described in Part I. As with the AFRI submissions, above, another Pardalis' Facilities, Resources and Equipment letter was attached to the ultimately successful USDA NIFSI submission. When you are doing your due diligence, ask to see the narrative to the USDA NIFSI submission under Objective 1. Develop a working, scalable stakeholder-driven “whole chain” agricultural commodity traceability system.[7] The work product from Pardalis' letter is clearly incorporated into the narrative of the USDA NIFSI submission.
The same work product is included in a composite fashion in Slide 10 of my August 2011 slide presentation, A New Way of Looking at Information Sharing in Supply & Demand Chains. It was included in the technology transfer proposal I made in November 2011 to Dr. Stephen McKeever, the OSU Vice President for Research and Technology Transfer, entitled Proposing Expansion of the National Institute for Whole Chain Traceability & Food Safety Research.[8]
There's more but I'll stop there.
2012
For two years permission was granted by me for OSU to use Pardalis’ work product on a handshake. The handshake signified that with funding the technology transfer issues would be dealt with in a win/win relationship between OSU and Pardalis. That win/win attitude was well represented in the article, Tracking and Incentivizing Data Sharing: The Whole Chain Traceability Consortium, posted by Food+Tech Connect in November 2011. But in January 2012 the hand shake agreement ended. Pardalis' database system was returned.
In April 2012 Dr. McKeever responded to an email message of mine. I followed-up with this question:
"Is work product and/or copyrighted material contributed by me and/or Pardalis continuing to be used by OSU without permission or compensation to build upon the success of the narrative of the funded NIFSI project in funding submissions made subsequent to [the termination of the handshake agreement]?"
I have to-date received no reply from Dr. McKeever. I’m not attaching that communication or linking to it here but it is time-stamped Sun, April 22, 2012 4:00 pm to Dr. McKeever’s OSU email address. In doing your due diligence, maybe Dr. McKeever will share a copy with you.
In June 2012 OSU announced that it was providing funding toward the formation of a National Institute for Whole Chain Traceability and Food Safety. This announcement included no attribution of any of the efforts or work products provided by Pardalis. Furthermore, the criticality of Pardalis’ work product to the proposed formation of the National Institute was at least in one instance in 2012 included in a promotional presentation made by one of the principal investigators of the National Institute. See the Slides 12 and 13 of the presentation by Dr. Brian Adam (entitled Whole-Chain Traceability – Information Sharing from Farm to Fork and Back Again) which was apparently shown in June 2012 to the National Value Added Conference in Traverse City, Michigan. Again, the inclusion of these slides was made without attribution to, or permission by, Pardalis. In fact those two slides used by Dr. Adam were personally prepared by me in 2011 and have been either untouched or barely retouched. The essence of Pardalis’ work product in extending the CTIDs envisioned by the IFT/FDA to the more granular CTIDs envisioned by Pardalis' patents clearly remains.
Conclusion
Whatever the reasoning or justification by OSU for the omission, the point of this blog post is to correctly attribute the proposed founding of the National Institute to Pardalis’ work product. No permission or license was given by Pardalis to OSU that would justify OSU behaving as if "whole chain traceability" had never been introduced and defined by me in 2010 for our research strategy. Moreover, there was no "work for hire" agreement. And following the termination of the handshake agreement there was no permission or license given to OSU to continue to use Pardalis' work product as if it were OSU's work product.
Due diligence advice
It is clear that the roots of the intended National Institute run deep into Pardalis’ work product but that this contribution has so far gone without attribution. And it is clear that OSU continued to use Pardalis’ work product without attribution in 2012 to promote the founding of the National Institute. If you are a researcher or company who is involved in activities connected with the National Institute, or you are considering becoming so involved, do your own due diligence investigation as to the behavior of OSU in using Pardalis’ work product without attribution.
What about the clear connection between Pardalis' work product and Pardalis' patents? Is OSU infringing the methods of Pardalis’ patents? Attribution doesn't solve this dilemma. The burden is on OSU to show that it is not infringing. If it is using Pardalis' patents then a direct, express license is required. If you are considering licensing or using any technologies that come out of (or are provided by) the National Institute relating to the networking of immutable informational objects then, again, do your due diligence research.
Closure
At my solicitation Dr. Sam Saguy of the Hebrew University of Jerusalem - along with several others[9] - graciously gave an early letter of support to the formation of the National Institute. Dr. Saguy said something that has stayed with me:
"It is worth noting that the ... founding of the Institute is truly a milestone made possible by the activities of the Whole Chain Traceability Consortium (WCTC). Unfunded, multi-institutional activities do not commonly coalesce and stay together for as long as they have with the WCTC. Keeping such a group together in advance of funding is no small challenge. The WCTC participants at Oklahoma State University, North Dakota State University, Michigan State University, the University of Arkansas, and Pardalis, Inc. have [implemented what I describe as] “sharing-is-winning” principles. Only through this open and mutual interests and sharing of resources most future hurdles will be overcome with fruitful outcome."[10]
Thank you, Dr. Saguy. I could not agree more
____________________
Endnotes
- This was the same database system that had been commercially deployed in late 2005 to a Texas livestock market. For more information see The Tipping Point Has Arrived: Market Incentives for Selective Sharing in Web Communications (July 2012).
- Background information. Not linked to or otherwise included here. If need be, you can ask Dr. Michael Buser at OSU for a copy of the SCRI submission.
- Email message to Dr. Deland J Myers, School of Food Systems, North Dakota State University, time-dated Tue, June 1, 2010 11:14 am from USDA\NIFA regarding Specialty Crop Research Initiative, Proposal Number: 2010-01167, Proposal Title: A Real-Time, Item Level, Stakeholder Driven Traceability System for Fresh Produce.
- It was at this time that I also personally solicited the participation of researchers at the University of Arkansas in the quest for funding by the “traceability consortium” then comprised at its core of Oklahoma State University, North Dakota State University, Michigan State University and Pardalis, Inc.
- The following picture was heavily influenced by Appendix I of the IFT/FDA Traceability in Food Systems Report, Vol. 1.
- See p. 4.
- You might also inquire as to whether the content in Objective 1 has been modified or updated from January 2012 forward to completely remove reference to Pardalis’ work product. See also the "due diligence" advice, below.
- See p. 3. By the way, proposing "expansion" of the National Institute was actually part and parcel of asking for more formal recognition of the National Institute by the OSU administration such as that given by OSU when it made its announcement in June 2012.
- See the updates to The Whole Chain Traceability Consortium (November 2011). Some or all of those letters - including Dr. Saguy's - may have been withdrawn or not used by OSU following the termination of the handshake between Pardalis and OSU.
- Letter dated 9 Oct 2011 to Dr. Brian Adam. Hyperlinked added.
 Steve Holcombe
Steve Holcombe
The presentation by Dr. Brian Adam which was apparently shown in June 2012 to the National Value Added Conference in Traverse City, Michigan (entitled Whole-Chain Traceability – Information Sharing from Farm to Fork and Back Again) has been removed from the Michigan State University server upon which it resided. I clicked on the link to the presentation on 24 January 2013 and received a "404 File Not Found" message. In doing your due diligence, you can always ask Dr. Adam for a copy. If you don't receive a satisfactory response, I know where a backup of the file can be found.
[UPDATE/April 9, 2014: See now this link.]
Steve Holcombe
I made a Freedom of Information Act request in January 2013 for a copy of the current narrative to the successfully funded 2011 USDA NIFSI proposal described in Part I. In response an electronic copy of the current NIFSI narrative was provided on 7 Feb 2013 by Stasia Hutchison, FOIA/PA Office, REE, USDA. Again, see and compare Pardalis' work product in Objective 1. Develop a working, scalable stakeholder-driven “whole chain” agricultural commodity traceability system (pp. 7 & 8 of the narrative) with Pardalis' Facilities, Resources and Equipment letter (dated 13 June 2011) which continues to be attached to the USDA NIFSI narrative.
Also, see and compare Pardalis’ Facilities, Equipment and Resources letter (dated September, 2010) that was attached to the 2010 AFRI STEC submission entitled Stakeholder-driven food supply safety system for a real-time detection, risk assessment, and mitigation of Shiga toxin-producing Escherichia coli [STEC] in beef products.
Steve Holcombe
Steve Holcombe
The essence of Pardalis’ work product clearly remains. Pardalis' work product continues to be used and cited without permission. See http://www.nwcti.com/documents/nifsi_project-narrative.pdf.
Steve Holcombe
That latest iteration of the website for the National Whole Chain Traceability Institute at OSU:
Steve Holcombe
That latest iteration of the website for the National Whole Chain Traceability Institute at OSU: