
Nova Spivack: Making Sense of the Semantic Web
The following video was taken of Nova Spivack at The Next Web 2008 Conference held April 3 and 4 in Amsterdam, The Netherlands. Other commentators have blogged on Nova's slideshow presentation given at the conference. See, e.g., Is Keyword Search About To Hit Its Breaking Point? (25 April 2008) by Erick Schonfeld, and Nova Spivack: "The Semantic Web as an open and less evil web" (3 April 2008) by Anne Helmond. I, myself, recently blogged on a statement of prior art filed by Nova Spivack and Kristinn Thorisson in a US patent application that I called Categorizing the Internet's Serious Problems (11 June 2008). For many of you, this latter blog may be a good starting point for what is to follow.
Because the video only became available in early June, I have been provided with an opportunity to blog on both the slideshow and the video at the same time. I have also included reference to substantial quoted text and, furthermore, you will find here the inclusion of two 'missing' slides. However, I would like to add that I am not blogging this as an opinion piece but as an addition to this blog's Reference Library. I'll blog my opinions in later entries.
I have stacked the video (42m07s) and accompanying slideshow (44 slides) one on top of the other, below, for those of you who have the time to listen and watch the video, and may want to jump back and forth between the two. The video irregularly shows where Nova is in his slide presentation, and often a slide to which he is referring is difficult to read or only partially shown. So having the slideshow available for quick reference should be useful.
I have included a substantial transcription of Nova's presentation beginning at Slide 17 (the 15m mark) through to the end of the 42m video and finishing with Slide 31. I have paid special attention to the time frame covering Slides 17 - 31 because Nova is then particularly focused on explaining the emerging mechanics and standards of the Semantic Web. Nova is a fast, fast talker (literally). I have taken care to accurately qoute Nova but if you find that I have mis-quoted him, please let me know.
Be aware that Nova does not orally present slides 32 through 44 which cover his product, Twine.
In addition to the embedded slideshow, below, I have obtained an updated version (dated 19 May 2008) of the same slideshow from Nova himself (Thanks, Nova!). I'm glad he shared it with me because there are two slides presented in the video that do not appear in the embedded slide show but do appear in the updated slideshow version. These 'missing' slides are presented by Nova after the 15m mark and so I have separately embedded them further down the page of this blog with accompanying quoted text. See the slides below entitled The Growing Linked Data Universe and The Growing Semantic Web, respectively. The updated version of the slideshow is in PPT format. You can download it from among the source references to this blog.
So, again, I have stacked the embedded video and slideshow below.
Nova Spivack at The Next Web Conference 2008 from Boris Veldhuijzen van Zanten on Vimeo.
Below you will find my transcription (i.e., numerous quotes from Nova's oral presentation) beginning at 14m56s, the missing two slides, and a few of my bracketed editorial comments. All quoted language is that of Nova Spivack's unless otherwise noted. All slide titles are emboldened and italicized.
14:56. Slide 17: Two Paths to Adding Semantics.
14:56. "There are two paths [to the Semantic Web]. One is called the bottom up approach, or classic approach, and that is where everybody is going to go learn RDF and OWL and manually create all of this semantic web metadata. It's not going to happen. It's really, really too hard ... The top down approach ... is to do this automatically [so that] the RDF and OWL code [is] embedded into the data - into the content - automatically [which] turns out to be more practical."
15:35. Slide 18: In Practice: Hybrid Approach Works Best.
15:55. Slide 5: The Higher Resolution Web.
[Nova jumps back to this slide in the embedded presentation. This slide was orally skipped over in the initial part of his presentation. In the updated version of the presentation (see above) this slide is numbered 16.]
15:55. "What we are doing is creating a higher resolution web. So it's like digital photography ... The semantic web is like saying we are going to give you ten times the number of megapixels in your data. So we are going to make a higher resolution web because each piece of data is actually going to carry more meaning ...."
16:47. "The way that Google sees the world is very flat. There are just basically pages and links. And that's all it really knows. In a semantic graph you know what types of pages or what types of things these data records are, and what types of links the connections really mean. Its a richer web meaning and we call this a semantic graph.
17:17. Slide 6: The Web Is The Database.
[Nova jumps back to this slide in the embedded presentation. This slide was orally skipped over in the initial part of his presentation. In the updated version of the presentation (see above) this slide is numbered 17.]
17:17. "Using the open standards the web becomes a database ... The [Semantic] Web is the database."
18:08. Slide 19: Smart Data.
18:12. "So we call [the data within the semantic web] 'smart data'. So smart data is data that carries what is needed to make sense of it .... So that you don't have to refer to some other application .... All that you need to understand to use that data is carried by the data itself ... You can make really, really dumb software but yet it can do really smart things ... because the intelligence is in the data."
18:53. "Ultimately we might have this piece of general use software that when you point it at semantic web data about health, suddenly it can give you medical advice. But then if you point it at semantic web data about data about the stock market, then it can give you investment advice .... That is the dream of the semantic web. All human knowledge will be on the web in a machine understandable fashion and then all software will be able to use all of this knowledge."
20:26. Slide 20: The Semantic Web Is A Key Enabler.
20:30. "Another concept is ... just in time data. The semantic web, because the data is self-describing enables and application to pull in data it's never seen before and use it right away. The challenge in the old-fashioned way of doing this is "what's the schema?" ... With the semantic web we do away with all of that annoying communication and simply the [smart] data tells you all of that. So it does that using an ontology. An ontology is like a schema. Basically, the data points to a document that describes its structure and the rules for using the data. And so when you see the data you go to the ontology [that is] written in the same language as the data and you can actually use that to make sense of the data without having ... to go read a schema document and then type that into the program.
21:45. Slide 21: The Semantic Web = Open Database Layer For The Web.
21:45. "[Another] way of thinking about the semantic web is that it is an open database layer for the web. So if we are making the web ultimately into an operating system ... [we can call the] Web OS ... it's going to have a file system ... and I think the semantic web is a candidate for that file system.... You should be able to write an application, point it at the web, get data, publish data and not care where it is ... You should be able to do this the way you do [this] on a desktop computer when you write an application ....
22:26. The semantic web standards provide a way of representing the schemas with ontologies, ways of representing rules, the data itself can be represented, mappings that say that this is the same as that can be represented, and there is also a query interface for doing searches in an open way across this data. So this is really a stack that creates a database layer for the web at large.
22:44. "So, this is really a stack that creates a database layer for the web at large. [Nova reveals Slide 22: Semantic Web Open Standards]. And there are several [semantic web] standards that are important. RDF is the main standard and that is really the way the data is represented with things called that are called 'triples' .... OWL is built on RDF ... [and] is just RDF with some more statements in it ... some more expressive power for defining schemas. SPARKL is a query language ... like SQL [but] for RDF. There's a rules language called SWRL ... that hasn't been standardized yet but there is a lot of talk now around the rules. And GRDDL which is for transforming data so you can say here is how to take this XML data and turn it into RDF on the fly. And you can make these GRDDL profiles for websites that enable anybody who wants to see [a] website in RDF to get the RDF [enabled version of the website] immediately.
23:56. Slide 23: RDF "Triples".
23:41. "Let's talk about how the data is represented .... The basic unit of data in the semantic web is called a 'triple' and that's because it has three parts. It has a subject, a predicate and an object. So, for example, "Susan works for IBM" ... [where] Susan - who is actually a URI that represents a data record that describes Susan - works for - which has a URI that defines what you mean by 'works for' somewhere in an ontology - IBM - which has a URI that points to a representation of IBM. Now these three things could be in different [databases] ... So, it's [like] a giant mashup on a very, very atomic level of data.”
25:10. Slide 24: Semantic Web Is Self-Describing Linked Data.
[Comment: Slide 24 represents a picture of a Data Record with an ID and fields connected in one direction to ontological definitions in another direction to other similarly constructed data records with there own fields connected in one direction to ontological definitions, etc. These data records - or semantic web data - are nothing less than self-describing, structured data objects that are atomicly (i.e., granularly) connected by URIs.]
25:14. "This [Slide 24] is illustrating how these data records are all connected together whether it is within one application or across applications. It becomes an open database just like the web but for data .... Is there a better term than semantic web? Yeah, it's data web. That's a better term."
25:35. Slide 25: RDBMS vs. Triplestores.
25:35. "The traditional way of storing data in a relational database would be [by] using [tables] and tables are annoying because they are not really the way we think .... You have to do all of these little tricks to make [data] point to other [data]. Now in the semantic version ... you just make a big list. [You create a] list of triples, each triple is a statement and has URI's in it. And so there's a challenge here that these lists of triples get really, really long. You could easily have a billion, or ten billion, or a hundred billion rows in one of these lists. And if you ... stick [such a] list into a relational database ... you get really bad performance because relational databases were not designed for data that has [billions] of rows and not many columns. Relational databases were [designed] for lots of columns and not as many rows. The optimization in the relational world was for a different shape of database."
26:28. "So to solve this we've created things called triple stores. These are new kinds of databases that are designed for these lists. These lists have a lot of benefits over the relational model. They're much easier to maintain, and they can actually live on top of relational database ...."
26:44. Slide 26: Merging Databases In RDF Is Easy.
26:44. "So one of the nice things about [the lists in the triple stores] is that merging data is extremely easy .... You don't have to do any fancy [relational] database refactoring .... [It is easier to use triple stores because] the way the data is integrated is through URIs.... If you have a URI for IBM [in one data record] and you have [the same] URI for IBM [in another data record], now we know they are referring to the same [data record for IBM]. And so the matching is done at the URI level rather than having [a] human sitting there and having to refactor the database. [Using URIs rather than humans] scales a lot better to the web ...."
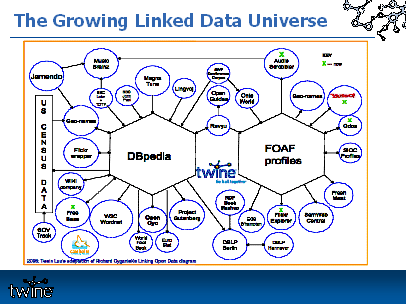
27:41. “Now there is this universe of linked data that is emerging .... and there are a number of different ontologies that cover different domains ... [see The Growing Linked Data Universe slide at 27:53, below] .... So there are a bunch of different ontologies and applications that all connect to each other and are sharing data in this growing web of connected data.”
27:53. Missing Slide: The Growing Linked Data Universe.
28:34. Missing Slide: The Growing Semantic Web.
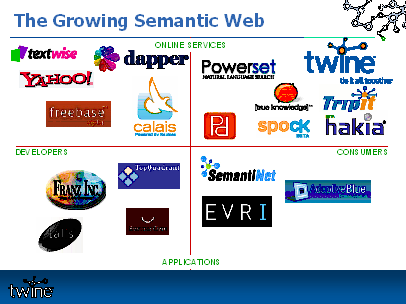
28:54. "You can see [referring to The Growing Semantic Web slide] a lot of activity around consumers right now and online services for developers and consumers. The applications side is starting to emerge in the enterprise space and that's kind of how it looks today."
29:04. “So where are we and where [is the Semantic Web] going .... [Nova reveals Slide 31: Future Outlook] Right now we are still in the early adoption period of this technology but there's a tremendous amount of momentum and a lot of adoption taking place among developers and also some early applications .... So I believe that this period of 2007 to 2009 is really the first wave .... [and during this period there will come to be a couple of million users or more of the semantic web] and then it will [be considered as] mainstream. So when we get into Web 3.0 [in] 2010 that's when real mainstream adoption happens. That's why I believe that semantics will be baked into a lot of mainstream applications from companies whether it is Google or Microsoft. Adobe already does it. Yahoo! already does it."
30:28. "Where the semantic web and data portability [project] meet is that the semantic web provides some open standards for making your data even more portable."
30:40. "[In conclusion the semantic web will] do for data what the web did for documents .... It's very hard to do this today because [while the standards are there in many respects] the tools are not [yet developed] and so if you have a company and you are thinking [that you want] to use the semantic web, it isn't easy. The place to start is [with] a few simple standards. One is called FOAF, it's friend of a friend, and that is for describing user profiles. Another one is SIOC, that is for sharing data about forums, discussions, [and] user accounts .... As you get deeper into the technology, and as more API's come out, and more services become open ... it will get much easier."
[Q & A]
32:48. "My personal opinion is that the semantic web does not introduce any new business models. I think that it just makes the existing business models better...."
38:06. Attendee's Question: "As far as I understood the semantic web it depends on definitions of different [things] .... If I understand correctly these definitions are done by people .... but before you also mentioned that people are really inconsistent so how do you [reconcile this]? Also how additionally do you handle the [definitions] of fast changing things?"
Nova: "Good questions. So there's a big misconception which is that the Semantic Web demands some kind of agreement. And you sometimes see that when people criticize the semantic web they say, "Well nobody's ever going to agree on a definition of ... all these things". In fact the Semantic Web was designed for disagreement. So, anyone can make their own ontology [and therefore] describe the world however they want. So that's a good thing but then it creates this problem that there might be many definitions. You know, here's my way of describing a car. Now over here this is how Toyota, Mercedes Benz, BMW describes a car. And it's different. So one of the things that they built into the standards was a way to map definitions to each other. So you can say [that] this definition is equivalent to that definition. You can also say [that] this piece of data is the same as [that] piece of data. So, anybody can make those mappings. Not just the people who made the data but anybody can make those mappings. And so in a community-driven, bottom up process, when mappings are created you can then begin to infer the equivalence or connections and in fact there's a lot of research going on that just from a few mappings you can make inferences that connect a lot of things together. So I think we will see something like the Wikipedia where lots of different definitions are composed and the winners will be the ones who have the services, who have the content, that uses that definition ... that get the most users ...."
[end]
 Steve Holcombe
Steve Holcombe
Reader Comments