
The problem of finding accurate, relevant, and appropriate information on the Web
The following quoted text (beginning at the bullet) is taken from the statement of prior art in US patent application entitled Knowledge Web filed in 2003 by Daniel W. Hillis and Bran Ferren. Knowledge Web is the IP being implemented by Metaweb Technologies in support of its product, Freebase. I previously blogged about Metaweb in The Funding of the Emerging Semantic Web. I've also blogged about the Knowledge Web patent application in US Patent App 20050086188: Knowledge Web (Hillis, Daniel W. et al) Φ.
- 1. Technical Field
The invention relates to knowledge. More particularly, the invention relates to a system for organizing knowledge in such a way that users can find it, learn from it, and add to it as needed.
2. Description of the Prior Art
There is widespread agreement that the amount of knowledge in the world is growing so fast that even experts have trouble keeping up. Today not even the most highly trained professionals--in areas as diverse as science, medicine, law, and engineering--can hope to have more than a general overview of what is known. They spend a large percentage of their time keeping up on the latest information, and often specialize in highly narrow sub-fields because they find it impossible to keep track of broader developments.
Education traditionally meant the acquisition of the knowledge people needed for their working lives. Today, however, a college education can only provide an overview of knowledge in a specialized area, and a set of skills for learning new things as the need arises. Professionals need new tools that allow them to access new knowledge as they need it.
In spite of this explosion of knowledge, mechanisms for distributing it have remained pretty much the same for centuries: personal communication, schools, journals, and books. The World Wide Web is the one major new element in the landscape. It has fundamentally changed how knowledge is shared, and has given us a hint of what is possible. Its most important attribute is that it is accessible--it has made it possible for people to not only learn from materials that have now been made available to them, but also to easily contribute to the knowledge of the world in their turn. As a result, the Web's chief feature now is people exuberantly sharing their knowledge.
The World Wide Web
The Web also affords a new form of communication. Those who grew up with hypertext, or have otherwise become accustomed to it, find the linear arrangement of textbooks and articles confining and inconvenient. In this respect, the Web is clearly better than conventional text.
The Web, however, is lacking in many respects.
It has no mechanism for the vetting of knowledge. There is a lot of information on the Web, but very little guidance as to what is useful or even correct.
There are no good mechanisms for organizing the knowledge in a manner that helps users find the right information for them at any time. Access to the (often inconsistent or incorrect) knowledge on the Web thus is often through search engines, which are all fundamentally based on key word or vocabulary techniques. The documents found by a search engine are likely to be irrelevant, redundant, and often just plain wrong.
The Web knows very little about the user (except maybe a credit card number). It has no model of how the user learns, or what he does and does not know--or, for that matter, what it does and does not know.
A Comparison of Knowledge Sources
There are several aspects to how learners obtain knowledge--they might look at how authoritative the source is, for example, or how recent the information is, or they might want the ability to ask the author a question or to post a comment. Those with knowledge to share might prefer a simple way to publish that knowledge, or they might seek out a well-known publisher to maintain their authority.
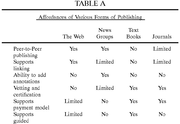 While books and journals offer the authority that comes with editors and reviewers, as well as the permanence of a durable product, the Web and newsgroups provide immediacy and currency, as well as the ability to publish without the bother of an editorial process. Table "A" is a summary of the affordances of various forms of publishing.
While books and journals offer the authority that comes with editors and reviewers, as well as the permanence of a durable product, the Web and newsgroups provide immediacy and currency, as well as the ability to publish without the bother of an editorial process. Table "A" is a summary of the affordances of various forms of publishing. Corporate and Government Needs
For institutions, corporations, and governments, failure to keep track of knowledge has consequences that are quite different from those for an individual. Often, institutions make a bad decision due to lack of knowledge on the part of those at the right place and at the right time, even though someone else within the institution may actually hold the relevant knowledge.
Similarly, within a corporation, the process of filtering and abstracting knowledge as it moves through the hierarchy often leaves the decision-maker (whether the CEO, the design engineer, or the corporate lawyer) in a position of deciding without the benefit of the best information. The institutional problem is made worse by the problem of higher employee turnover in the more fluid job market, so that the traditional depository of knowledge--long-standing employees--is beginning to evaporate, just as the amount of knowledge that needs to be kept track of is exploding.
The consequences of not having the right knowledge at the right place and time can be very severe: doctors prescribing treatments that are sub-optimal, engineers designing products without the benefit of the latest technical ideas, business executives making incorrect strategic decisions, lawyers making decisions without knowledge of relevant precedents or laws, and scientists working diligently to rediscover things that are already known--all these carry tremendous costs to society.
The invention addresses the problem of providing a system that has a very large, e.g. multi-petabyte, database of knowledge to a very large number of diverse users, which include both human beings and automated processes. There are many aspects of this problem that are significant challenges. Managing a very large database is one of them. Connecting related data objects is another. Providing a mechanism for creating and retrieving metadata about a data object is a third.
In the past, various approaches have been used to solve different parts of this problem. The World Wide Web, for example, is an attempt to provide a very large database to a very large number of users. However, it fails to provide reliability or data security, and provides only a limited amount of metadata, and only in some cases. Large relational database systems tackle the problem of reliability and security very well, but are lacking in the ability to support diverse data and diverse users, as well as in metadata support.
The ideal system should permit the diverse databases that exist today to continue to function, while supporting the development of new data. It should permit a large, diverse set of users to access this data, and to annotate it and otherwise add to it through various types of metadata. Users should be able to obtain a view of the data that is complete, comprehensive, valid, and enhanced based on the metadata.
The system should support data integrity, redundancy, availability, scalability, ease of use, personalization, feedback, controlled access, and multiple data formats. The system must accommodate diverse data and diverse metadata, in addition to diverse user types. The access control system must be sufficiently flexible to give different users access to different portions of the database, with distributed management of the access control. Flexible administration must allow portions of the database to be maintained independently, and must allow for new features to added to the system as it grows.
It would be advantageous to provide a system to organize knowledge in such a way that users can find it, learn from it, and add to it as needed. ....
While the invention herein is directed to solving various problems with regard to using, managing, and accessing information, three specific problems are identified in FIG. 1.
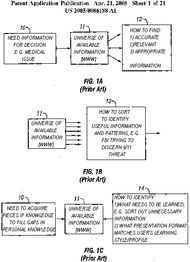
[Original image modified for size and/or readability] In FIG. 1a, a user 10 needs information to make a decision, for example with regard to a medical condition. The user accesses the universe of available information 11 which, in this case, could be the World Wide Web or other sources of information. A process 12 is required in this regard that would allow the user to find accurate, relevant, and appropriate information.
In FIG. 1b, the universe of available information 11 exists and a process is required for searching the information to identify patterns of information that are useful, for example a government agency trying to identify a pattern of information that might predict a security threat.
In FIG. 1c, a user 10 needs to acquire particular pieces of knowledge to fill gaps in the user's personal knowledge. When accessing the universe of available information 11, a process is required that allows the user to identify what needs to be learned and what information is extraneous and therefore need not be considered. The process 14 must also present the information in a format that most closely matches the user's preferred learning style and/or intellectual interests."


 Steve Holcombe
Steve Holcombe
Reader Comments