This is a transcription for filing in the Reference Library to this blog of the substantive dialogue found in Episode 12 of the DataPortability: In-Motion Podcast. The series is co-hosted by Trent Adams (TA), founder of Matchmine, and Steve Greenberg (SG), CEO of Ciabe.
The guest in Episode 12 is Drummond Reed (DR). Drummond is a founding Board Member at the Information Card Foundation, Vice-President of Infrastructure at Parity Communications, a member of the Standards Committee at Project VRM, a founding Board Member at OpenID Foundation, Co-Chair of the XRI Technical Committee at OASIS, the XDI Technical Committee at OASIS, the Secretary at XDI.org, and a pioneering inventor from as early as 1996 of certain ‘data web’ patents when, no doubt, it was difficult for Drummond to find anybody who actually knew what he was talking about. Well, now he has an audience and deservedly so.
The transcription picks up at the 6:50 minute mark (after announcements and banter between Trent and Steve) and goes straight through to the 50:01 minute mark when Drummond leaves the stage.
6:50 TA “… another great step that was announced this week is the launch of the Information Card Foundation.”
6:55 DR “You bet … I’m here actually at the Burton Group Catalyst Conference [held in San Diego, June 23 - 27, 2008] where [the announcement was made and we] got a really good reception. This is [a] very enterprise facing audience but I think actually that’s part of the message of what information cards are going to do [which will be to] bridge enterprise, identity and access management requirements with ... web scale requirements. So, it’s something that is, I think, important from the standpoint of data portability but also hooking it into …. enterprise systems and a lot of places where data resides and people are going to want to share it but very carefully.”
7:38 SG “So can you give us an overview of what info cards actually are?”
7:45 DR “Information cards are primarily first and foremost a visual metaphor – a consistent visual metaphor – for identity interactions. And this is intended to be across any device, and potentially – the way the Higgins Project is approaching this – any protocol. So they can be protocol independent meaning that I … can use and information card on my PC to log into a website … that will behind the scenes use the WS star stack protocol that Microsoft, and IBM and others have been driving. But I could ... use an iCard on an iPhone and be sharing a card directly with a friend and in the background that form of a card might use XDI as a protocol …. There’s even work [going on] to use iCards with OpenID. So it is first and foremost a visual metaphor and it’s based on a very simple concept which is the same thing we use for identity and sort of a basic form of data sharing - we might call claim sharing - in the real world which is you’ve got a wallet with a set of cards in it, and when you need to go someplace and prove your identity or give them some basic information you take out your wallet, pick the card that will work for that transaction, and ... give a copy to the other party, and they accept it or not, and that’s all there is to it.”
9:29 SG “So the big idea here is that it’s a standardized set of tools and APIs that developers can build to that supports various forms of identity, and that rather than having to rebuild ... a custom connector for every site you just write to this one API and then whatever the user has you can figure out a way to work with [it].”
9:54 DR “Yes, that’s very true and as you know, Steve … I’m working a lot now with the Higgins Project and what you just described is almost a perfect definition of what Higgins is about which is ... an identity framework but it’s primarily an abstraction layer to hook into almost any kind of system with what they call context providers - you know, a form of adapter into that system - to expose the data in the way it can be shared and the most common … interface that you’ll use to access a Higgins repository - that has a Higgins interface - to either pull out or put in some data is going to be information cards …. The whole purpose of the Higgins API is to give developers ... one API they can use to access identity data and potentially ... take it from one place and move it to the other – which is where it intersects with data portability. But to give one API to do that any place you want … that’s why it’s a big project.”
11:25 SG “So this is sort of an essential component of the OASIS data web, right?”
11:32 DR “It’s definitely a key implementation of [the OASIS data web]. It’s probably the text book implementation, right.”
11:39 SG “So can you talk to us for a bit about what [the] ‘data web’ actually is?”
11:43 DR “Sure, sure. Exactly …. The concept is pretty simple. We all know what the web has done for content, right? It’s turned our world upside down in the last fifteen, twenty years. And there’s an increasing need … to say that the web works great for content, for human readable … information, but can we apply the same concepts of interlinking and … this tremendous, unprecedented interoperability across domains? Can we apply that to ‘data’? You know, can we get it down to the point where machines can navigate and exchange information under the proper controls the way humans can today by …. If I want to browse over a whole set of documents … I am as a human selecting for this document, reading links, deciding what is relevant, and then choosing the next link I want and then activating that link and going to the next site and so on. That’s tremendously powerful but can … we get to the point where the data is understandable by a machine so a machine can follow the data – follow the links – in order to carry out something that a human wants to do without a human having to guide every decision. And to do that you have several requirements. To take the web and apply it to data … it’s a hard problem. It’s a very attractive solution. I mean that’s what got a bunch of us involved with this but it turns out there’s some real challenges and piece by piece that’s what we’ve been working on in two [indecipherable], in OASIS, and also other pieces of Higgins, and folks all over. There are a bunch of related efforts that now fall under the rubric of the data web.”
13:54 SG “And one of those, which you are also deeply involved in, is the XDI project. And that’s an enabling technology for the data web …. Why don’t you tell us about how XDIs fits into all of this and how link contracts [work] …? How does one bit of data actually connect to another bit of data?”
14:21 DR ”Yeah, exactly. I love the way you put that because in the context of data portability – I mean, ever since I first heard that term, data portability ... wearing my XDI TC [XDI Technical Committee at OASIS] hat I said ‘oh, my god’ that’s like the mission statement for the XDI technical committee in two words. What did we never just say, ‘hey, look’ its just data portability? It’s going to enable data portability. Well I can think of a couple thinks. Again, that’s why we call it data web because there are other things that the data web will enable but if there is one thing that is a headline feature it’s data portability. And so it’s very simple at a high level to explain what is XDI. XDI is a protocol for sharing data just like HTTP has become a protocol for sharing contents … And I have to clarify .… The web really is comprised of three pieces: [HTTP, HTML and URIs]. It’s those three things that created the web, and those of use working on the data web have long said that we needed … to take each of those three things and basically add more structure. The data web is increasingly being called the ‘structured web’ because you need to … add more structure to the documents so instead of HTML documents you need a more structured document format … It’s really a database format is what you’re putting on the wire with XDI as a protocol. And then you need more structure to the links. The links have to be able to granularly address the data … anywhere on the data web. So, it’s not enough to just say ‘here’s a document’ and, then, oh, there’s a hash line if you actually want to point to some anchor, some bookmark, inside the document. That’s what web addresses can do today. They can get you to a document and then if you want they can get you to one point inside that document but if you want to go any further … if you wanted to pass around an hCard or a vCard … in the classic data portability sets, well how do you address the … ‘zip code’ inside that? And if you have a phone number [that is structured] how do you address the area code? Database technologies have a way of doing that. Even XML and XPath provide you with a way to do that. With the data web you have to essentially be able to address data at any level from the smallest atomic field … to the largest collection … which have been called ‘data web sites’ …. So if you theoretically took … an existing data base and put it on the data web it would be very much like hooking up existing content repositories. An example. Take newspaper classifieds. Put them on the web and suddenly you can display them all as HTML pages, right?”
17:54 SG “So the way I sort of try to explain this to people is if you think about what SQL is …. A SQL query is the programmer … describing to the system what the data he wants back looks like, right? So based on attributes of the data, based on … samples or fields, you say to the system [to] go out, look at all your data and give me the stuff that looks like this. And … specifying … the what rather than the how…. And this is sort of the way of applying that same metaphor to all the data that lives on all the various sites that may not even know they’re connected to each other.”
18:41 DR “Yes, exactly. It’s literally … some of the folks on the XDI TC do look at as SQL taken to the web wide level, so whether it’s SQL or whether it’s … LDAP, when your talking to a directory system then you usually using … a directory access protocol like LDAP.”
19:05 SG “But LDAP is hierarchical, right? So that to me is always the difference is that … you have to know the structure of the initial data store to work with LDAP whereas if you look at something like SPARQL or SQL you just say, if one of these things is connected to one of those things and its got these attributes and there’s five of them, tell me about it.”
19:34 DR “Yeah, exactly.”
19:36 SG “Describe the sort of thing that you want to get back ….”
19:40 DR “Yep, and one of the deliverables – the XDI TC just updated it’s charter a few months ago – and we …. have now separated out one of the specs that we’ll be coming out with is a data web query language and it’s … to be able to query any repository on the data web in the same way. And … whether it’s an LDAP directory that was exposed or a SQL database that was exposed or an XML document or an object or any database in place [they all] could be mapped into the data web, and all of them could respond to a query … in XDI format.”
20:27 SG “So that’s interesting. So would you extend XSL to do that? Or how would you actually do that?”
20:34 DR “You mean the actual format? The XDI documents? And queries and all that?”
20:38 SG “Well, I’m just wondering …. If you don’t know in advance what the document is … would you specify the query in terms of an XPath plus an XSL transform or how would you tell it …?”
20:57 DR “That gets right to the heart of … XDI as an architecture for the data web. And quite honestly it took us … TC [i.e., XRI Technical Committee at OASIS] is almost five years old …and our first specs won’t be coming out until this fall, and I know a lot of people who have said … so what have you even been working on? What’s taken so long? Well the [XRI Technical Committee at OASIS] knew that what it needed to do to create the data web …. Just as without HTML you never would have had the web. What HTML did for the web is it said, here’s the universal characteristics of …. content documents. And you look at HTML and … a lot of people, when HTML was invented it was a very, very simple variant of SGML … that a lot of people had never even heard of …. And it was like ten years before the web there was this huge language [i.e., SGML] that was being used by big companies [like Boeing] to exchange extraordinarily complex data …. HTML was this [little, tiny, very simple language that was, like,] one percent of the capacity of SGML that Tim Berners-Lee and his associates came up with for the web but what they did is that they just extracted […] OK, what are the universal characteristics of documents, you know? They have headings, they have paragraphs, they have bulleted lists and numbered lists and … it ended up being about thirty, forty elements and surprise, surprise with the addition of a few things as the web started to grow, it’s worked through all contents, right? I mean … so the power they tapped into was by saying, OK what are the … universal characteristics? Even though it’s not incredibly rich, the power comes because everybody can use it. Every browser can talk to every web server, right?”
23:10 SG “Well, the key insight was to apply standardization to the data so that you could write any program you wanted … that could talk to the data which is the exact opposite of the way things had been done before.”
23:23 DR “Exactly. There you go.”
23:24: SG “Which is … one of those forehead slappingly (sic) obvious things that only the most brilliant person in the universe can point out. It seems so obvious after the fact but for those of us working … in the industry in the late 80s and early 90s … when that first came out we all went, oh, my god who could no one have seen that … give that guy a Nobel prize.”
23:54 DR ”Exactly … so what the XDI TC came together around was saying, OK, we need to do the same thing for data. And what we really need to do is we need to get down to what’s often been called a common schema which sounds like an impossible journey but it’s like … the whole point of data in all these repositories is that it’s in all these different schemas that are in some cases designed for the repositories – you know, to optimize like LDAP schemas and directories – or in some cases they’re designed to be very generalized but still to, you know, like SQL and relational databases – to … have wonderful search characteristics … and everything else and other repositories [and] object oriented [repositories] and other specialized [repositories] and all these different schemas and here we’re saying, well, we need a common schema so that we can access the data, deal with the data, wherever it is in whatever schema it may be … in its native repository.”
24:57 SG “So does Dublin Core help with that?”
25:00 DR “No, actually Dublin Core is a common ontology …. It’s a set of characteristics of content objects …. You could say books, web documents, basically anything that is a document or a content object of some kind. What Dublin Core was trying to do was say, what are the universal characteristics [of a content object]. It’s got an author, it’s got a creation date … [and it’s got] basically sort of universal bibliographic characteristics ….”
25:45 SG “So how do you contrast [XDI] against the characteristics of what you were talking about a second ago?”
25:50 DR “What we’re talking about [is] a common schema, a way of describing the data itself in whatever repository it may be in such [a way] that you can …. The ultimate goal is to be able to take the bits – the very exact bits – that sit in repository A – whatever kind it may be – extract them in such a way that they can be understood and ultimately moved to repository B which may be the same thing – you might be going from one SQL database in one system to another SQL database in some other system – but you might be going from one SQL database to an LDAP directory someplace – or you might be going from an XML document into an object oriented repository.”
26:35 SG “So whereas the Dublin Core stuff is concerned with the semantic elements of a document, you’re actually concerned with transforming the data from a usable representation in one system to a usable representation in [another] system.”
26:55 DR “Yes”
26:56 SG “So how is that not XSchema?”
26:58 DR “Yes … fundamentally, what you [have] a problem of is schema translation or schema transformation. In other words, XML and XML schema tackles the problem of taking the data from its native format and putting it into XML with a schema that either reflects the schema that it came out of or puts it in whatever that XML schema is. So you have now a schema description language. And a common representation format [which is] a grammar in which you can access and move the data around. So if you can take the data, for instance, again, out of an LDAP directory and put it into an XML format, and you have a schema designed to do that – in fact OASIS produced one of those … the SML - now you can take that LDAP data and put it in an XML document and systems that understand that schema can then move that data around. So that’s what the SML was created for …. [It was created] for interchange of data between LDAP directory systems. OK, so we’ve gotten that far with XML. We’ve got a schema description language which now you can put an XML document itself (sic) so you can even exchange the schemas, but what you haven’t solved is the problem of moving data from … a schema in one system to a different schema in another system. That’s the problem … you actually have to solve … if you want to achieve data portability that’s not tied to any one schema format. And that’s a classic [problem]. Ever since I heard of the Data Portability Initiative and [wondered] how XDI would be … relevant … I have been waiting and watching to see how folks would start to key in on the schema problem.”
29:11 SG “Well, this is why I was asking before about using XSL because it seems to me like if you can get the data into XML as a transitional format – where you use XSchema to get it into XML – you could then use XSL transforms to make it look like whatever you want, and then use another XML schema to turn it into the target anything (sic).”
29:39 DR “What you just described is a perfect setup for … the [ultimate] problem that the XDI common schema format actually solves. So, take the different systems … the tens of millions of systems that exist out there … now, most of those systems are not one-off systems so … many of them are using some vocabulary whether its all the LDAP systems are using (sic) could put there’s into DSML so you could understand the LDAP schema but when you move to relational databases [and] object databases they have … thousands and thousands of schemas designed to hold their data so now imagine … the end to end problem you have of taking data out of one system – its in one schema now in XML – and now you’ve got to come up with the XSLT transform to get it into ten thousand other systems, right? And each of those ten thousand other systems has to be able to talk to ten thousand other systems. And just imagine the number of transforms you’re going to have to come up with. It’s pear-wise mapping, and it just goes exponential.”
30:53 SG “So I guess what I’m not getting is if it’s not a one to one map how does this actually work? Can you describe to me the process of how … the transform actually takes place?”
31:07 DR “Well … what I was just describing was if you take the transform approach but its end to end and therefore goes exponential between all the systems, to contrast that the XDI approach is to say, OK, we’re coming up …. What we’ve designed is a common schema …. It’s an incredibly simple schema because it really goes down below the layer of conventional schemas and says there’s an atomic set of relationships between data … there’s a way of describing those relationships that is universal ….”
31:42 SG “And what would some of this be? Would it be like an RDF bag or an RDF seek?”
31:46 DR “Yes … now you are getting down to the stuff … where it’s really hard to put this stuff in words that are going to make sense to a lot of the audience. It’s easier to talk in analogies …. The schema that we have come up with – which we call XDI RDF – is in fact an RDF vocabulary. However, it’s very different. We’ve got a number of RDF folks on the [XRI Technical Committee at OASIS] and I’ve been talking with other RDF experts outside the [XRI Technical Committee at OASIS] about XDI RDF and as sort of what you would expect, they’re looking at it and going, mmmm, that’s not a conventional RDF [because] no one’s been thinking about this approach to it. An RDF vocabulary … in which there is a primitive set of relationships – very, very simple relations that are described – predicates, is the RDF term for it – and, but those predicates actually …. every identifier that you use in XDI RDF is itself built up from these predicates …. so … in conventional RDF you have subject, predicate, object, triples, right? Everything is described in triples and if you can use those triples to describe all the data … wherever it might [be] whether its in a web document or an LDAP repository or all these things that might be on the data web, the “Semantic Web” approach is describe them all in triples and then everyone is going to be able to understand everyone else’s, your going to have this Semantic Web of information because it’s now all described in a common way [because] everything is in triples. And … that’s one approach you might say to the common schema format which is to say, well, if you put it all in triples where you have a way for every system to expose [these] triples now everyone can talk to everyone and they can talk right down at the level of the data. You can make it as granular as you need, right? And everything is in triples … everything is in RDF documents, right? And that is a solution … the Semantic Web is one solution, I think a very powerful one, to the common schema … problem. The twist on it that XDI RDF introduces is to go a step further and say, OK, with … RDF documents you still have the problem of vocabulary mapping which is, OK, if you take an RDF document … in an LDAP repository then its going to be using a set of RDF statements – a vocabulary is what they call it – to describe data in LDAP terms and if you went over to a SQL system and they designed … an HR [i.e., human resources] repository then they are going to have RDF documents now, everything’s in triples so its in a form you can understand but its still [has] its own vocabulary, and how does the system in the LDAP repository understand the HR vocabulary and how does the HR … system understand the LDAP vocabulary. So you have this vocabulary mapping problem. What the XDI RDF approach [does] is it says, OK, we are going to take another step which is all of the …. [Let me back up], in conventional Semantic Web, these triples are all formed from URI’s [which are] web addresses [and therefore unique] …. Every subject is a web address. Every predicate [is a web address]. An example [would be] an hCard [where there is a URI that describes the hCard]. And then for each part of the hCard, each predicate, it would say, OK, this is an hCard and this is a person’s name and then the object is the person’s name … and then here’s their phone number [identified by a URI] and then [here is the] value of the phone number, right? So that’s the vocabulary and the set of URI’s you end up with that describes the data is called the RDF vocabulary, right? So, in XDI RDF we don’t use flat identifiers instead … the identifiers themselves are built up, they’re structured identifiers, and that’s why XDI is based on XRI which is a structured identifier format and those identifiers themselves define … the data, and they define the relationships between the data, and so if you took an hCard and you put it in the XDI format then you are still going to end up with the subject, predicate, object but the identifiers … those predicates that say, this is a name, this is … a telephone number, this is a zip code … you can turn around and every one of those identifiers you can say a piece of software can look at it and say, mmmm, I don’t know what that is. I’ve never seen one of those before. You can take that identifier and you can go look up the definition and the definition will also be another XDI document and you can work your way back all the way through and the … definitions break this down into this low level grammar which is this common schema for describing everything out there. So with the dictionary approach because you have been able to break things down to these atomic relationships the LDAP system can now describe the relationships its making … between ultimately these atomic fields of data and the relationships [of the] higher level objects that it has, it can describe them in a way that literally in XDI documents – those descriptions [and] those definitions – can be described in such a way that an XDI processor over at the HR system can literally look over at the dictionary, look through the dictionary, understand the relationships such that … a human programmer does not have to sit down and work out the XSLT transformation between data that is in the LDAP system to the HR system.”
39:22: SG “Well when you say ‘dictionary’ its almost more like it’s a periodic table, right? That you’ve got these molecules of data and now that I know what it is I can say, oh, I now know the characteristics of this thing because I have its atomic number.”
39:39 DR “Yeah … I really appreciate that, Steve. I think you just … the dictionary uses a sort of human semantics but we’re actually much more down to physics, here, and its true that … the ultimate semantic thing that you are doing is that you are going to take the bits that comprise a phone number in the LDAP system and you are going to map them to the bits that ultimately need to reside in the HR system that describe a phone number but happens to … literally, the schema of a phone number is different in the HR system than it is in the LDAP system. But we’re down to the level where clearly as long as you provide adequate descriptions at that atomic level table that this is what machines were designed to do, right? Oh, it’s described this way here, and it’s described that way there. They [i.e., the machines] figure out the transform. The human doesn’t have to do the transform.”
40:32: SG “Right, so I know if I get a molecule that has the atomic weight of [a] ‘phone number’ then this is what I do with it. I know what to do with the phone number.”
40:41: DR “Exactly, exactly so really … in fact … the atomic table, I think I am going to march forward and start using that because literally now you can start to see that any system that now wants to say, OK, I really want to support data portability. I really wanna make data available in a way that other systems can understand it. They sit down once and provide their mapping to the atomic table. And … again, their mapping, they may have things that … schema elements and combinations and things that exist only in their system. They don’t exist anywhere else in the world. And that’s cool. That’s there value add but if they want to make that data digestible in other places …. If they provide that mapping then XDI software and XDI agents can go access it and figure out what the transforms are … figure out what … they can understand, what they can use. Now we can have real data portability.”
41:37 SG “So the XDI would say that a US postal code is five … numbers with a possible dash and then four more numbers. A Canadian postal code might have some letters in there, right? So … you’ll know how to handle them. That’s neat.”
42:00 DR “Exactly, because you have taken them all the way down to the A, B and F (sic) of the respective systems. And that’s the level of which, again, when I talk about XDI dictionaries I talk about software that is designed to express the data, but it’s more than that [because] there’s going to be dictionary agents that handle the job of semantic mapping across systems.”
42:22 SG “OK, so now that we’ve talked about how to transfer things between, how do control who can see what, and who can‘t?”
42:32: DR “Exactly. So here’s the batta-ba-boom (sic) of all of this. The part about XDI that has gained the most interest since it was TC was first announced was this capability we call ‘link contracts’. And, ultimately, what link contracts [may be described as is a] Web 2.0 or Web 3.0 term for portable authorization. How systems can control … access … and usage of the data in the system … but also how that control could be portable to another system, and will make this immediately relevant to … issues that are right at the core of data portability, for instance. If an individual starts using a service provider to store a bunch of their personal data, what VRM calls a personal data store, and you start storing a bunch of personal data, and you start sharing it using protocols … whatever the protocol is but imagine using XDI and start to share it with a bunch of systems like a bunch of vendors who all want to subscribe to your phone number, right? The biggest challenge after you solve the problem of how you actually would … move the data – once you solve that semantic problem – is control. How do you say, what … vendors can have the information and what they can do with the information? What is the associated privacy policy or [associated] usage policy? In a way that not only vendors can understand but you could turn around and move to another service provider – another provider of a personal data store – so that you’re not locked into one provider in that way that one provider controls access to the data on their system. How can you have a portable way of handling authorization?”
44:25 SG “So talk about … what that would look like. How it would actually work?”
44:29 DR “Well, so, the secret really is [about] these things [like] access control …. Applying those forms of policy to the data are very, very well understood in directory systems and identity management systems …. I’m here at the Burton [Group] Catalyst Conference and there’s just session after session about how this is done in enterprises all over the world. The challenge is in order to make it portable …. No one’s ever made it portable. The LDAP community is the oldest …. Goes back … to X.500 … [which was the] biggest directory effort in history and they ultimately punted on the problem. They could not come up with a solution for how one LDAP system could describe access control to another LDAP system. So you could literally move not just entries from one LDAP directory to another but control over those entries. Who could access what? It’s never been solved in LDAP. Well I believe the answer is that it’s never been solved because … even in the same system you had to come down to a common … graph of information because … the only way you can describe control over information is to have pointers to that information that don’t change when you move from one system to another.”
45:50 SG “But it’s a common graph of not just the information but also the identity[, right?] The ability to say that … both systems can know that the actor who is setting or requesting information is actually the same person[, right?].”
46:05 DR “Exactly. Actually you have to have three things in common, OK? You have to describe the data in a way that both systems can understand it [so that they] can be pointing at the same thing …. This is Steve’s phone number, OK? So you have to be able to identify [that] this is Steve in a way that both systems can understand. You have to be able to identify that this is Steve’s phone number in a way [that] both systems can understand, and then you have to be able to describe the control that Steve is providing which is to say Trent can have access to this phone number on both systems. And, so, yes, you have to solve the data problem, you have to solve the identity problem, and you have to solve the control problem, and XDI link contracts solve that …. First of all, XDI is a protocol …. A big step beyond the common format is that in XDI …. there’s a sender and receiver of every message as there is in e-mail, so identity is built into the protocols …. There is anonymous access to the system but the identifier is for an anonymous accessor. [In the] vast majority of XDI transactions …. it’s not an IP address that is addressing the system, it is an identity. You know … take MySpace …. If MySpace starts exposing data in XDI then … they can identify, oh, this is Steve accessing his own account on MySpace. Oh, this is Trent accessing Steve’s account and you authenticate as you’re Steve or you’re Trent and they then know because they know they have a way of describing the permissions that apply to that data what they give to Steve because its his account [and] what they give to Trent because Trent is a friend of Steve’s.”
47:55 TA “Only if in fact I was a friend of Steve’s.”
47:58 DR [Laughs]
47:59 TA “So there needs to be an enemy control in there somewhere as well.”
48:02 SG “Hey, do you want me to come back next week?”
48:04 TA “I keep pushing my luck, and speaking of pushing our luck, I think we’re pushing our collective luck here by locking Drummond to the phone when he’s got to skedaddle over to the Catalyst sessions.”
48:15 DR “At least we got to the heart of … link contracts [and] portable authorization which I do want to say just this one final thing …. So the two hardest problems [as I have been watching the Data Portability initiative] are the common schema problem and the authorization problem – portable authorization problem. And … so I just really want to thank both of you for this opportunity …. As you can tell, I am very passionate about this topic. To talk about … well, there is this effort at OASIS … to solve both [of] those problems with the XDI protocol and the XDI link contracts and … I just wanna let you know, hey, we’ve made a lot of progress …. We’re no longer in the, OK, figure out the problem stage. There are actually two implementations of XDI. One of the first module (sic) we worked out [is] called [the] ATI model which is available from a company call ooTao. They actually have a commercial XDI server that does that and then the XDI RDF model has been implemented at Higgins in a module called XDI for Java and if you just Google XDI 4J or XDI for Java … Higgins and XDI, you’ll get to the pages there, and that module is [a] stand-alone XDI module that you can already start to play with. You can validate XDI documents. You can send and receive XDI messages. You can set up your own end points. This is real stuff now. So we are very excited to … get the specs out and actually start to show folks here’s how you could have data portability that runs everywhere.”
50:01 SG “That’s great. One ring to rule them all.”
[Drummond leaves the stage. Finishing banter]
The following is printed verbatim from a 6 September 2008 blog entry in Equals Drummond by Drummond Reed entitled XRI in a Nutshell:
XRI IN A (REALLY SMALL) NUTSHELL
XRI is an identifer and resolution infrastructure just like DNS, except that it operates at a higher abstraction layer, just like DNS operates at a higher abstraction layer than IP addressing. XRI is to URI addressing (of any kind) what DNS is to IP addressing.
At the DNS layer, the resolution protocol is UDP. At the XRI layer, the resolution protocol is HTTP (or HTTPS for security - more on that below).
In DNS, you resolve a domain name to an RR (Resource Record). In XRI, you resolve an XRI to an XRDS document.
In DNS, the server hosting RRs for DNS zones is called a nameserver. In XRI, the server hosting XRDS documents for XRI authorities is called an authority server.
Just as DNS names can delegate to other DNS names (e.g., in www.yahoo.com, com delegates to yahoo delegates to www), XRI authorities can delegate to other XRI authorities. In XRI the delegation characters are not dots but * (for reassignable XRIs, called i-names), and ! (for persistent XRIs, called i-numbers). So the XRI i-name =drummond*foo is a delegation from my XRI authority to another one called foo. And the XRI i-number =!F83.62B1.44F.2813!24 is a delegation from my i-number to another one called 24. (Authority delegation is handled in XRDS documents using the service type xri://$res*auth*($v*2.0).)
In the resolution spec, we define two kinds of XRI resolvers: local and proxy. A local XRI resolver is just like a local DNS resolver: you call it with an XRI and a set of resolution parameters (like the service type you’re looking for and whether you want it to use trusted resolution or not) and it gives you back (depending on what function you call) the entire XRDS, the final XRD, the final XRD filtered for only the service you want, or just a list of URIs from that service. A reference API for a local resolver is provided in Appendix F of XRI Resolution 2.0.
A proxy resolver is simply an HTTP(S) interface on a local resolver, so you can call it over the net like a service. This interface is defined in section 11 of XRI Resolution 2.0. To call a proxy resolver, you embed the XRI you want to resolve in an HTTP or HTTPS URI and then add query parameters to control the resolution result you want back. The resulting HTTP(S) URI is called an HXRI.
The ABNF for an HXRI is in section 11.2 of XRI Resolution 2.0. But it’s really simple: a) you create a prefix of http://xri.*/ or https://xri.*/, b) you append the XRI you want resolved as the path (without the xri://, and c) you add any XRI query parameters.
http://xri.net is just a XRI proxy resolver run by XDI.org as a public service (NeuStar actually operates it). But there are other proxy resolvers, for example, http://xri.freexri.com (see @freexri for more). Anyone can run an XRI proxy resolver just like anyone can run a DNS server. There is no one authoritative proxy resolver.
So when you see http://xri.net/=drummond in my email sig, that’s an HXRI. It’s jus the way to ask the the http://xri.net/ proxy resolver to resolve the XRI =drummond. If you don’t give it any resolution parameters, what the proxy resolver will return is a 302 redirect to the HTTP(S) URI for whatever resource I have designed to be selected as my default service (in my case, my contact page at http://2idi.com/contact/=drummond). But if you add resolution parameters, you can get back anything the proxy resolver supports. For example, the following HXRI will give you back my XRDS:
http://xri.net/=drummond?_xrd_r=application/xrds+xml
Lastly, since you bring up security, there are two key trust features of XRI infrastructure that are good reasons to use XRI with OpenID Authentication 2.0. The first is trusted resolution. XRI infrastructure supports three modes of trusted resolution: 1) all-HTTPS resolution calls (meaning every step of the resolution chain across delegations uses HTTPS automatically), 2) SAML signatures (meaning every step of the resolution chain returns an XRDS with a SAML signature), and 3) both HTTPS and SAML. See section 10 of XRI Resolution 2.0 for details of all three. (Note: HTTPS is supported by 100% of the XRI authority servers I know of, but SAML support has so far has been limited to special cases.)
The big advantage is that since XRIs are abstract identifiers, any OpenID RP can choose to use 100% HTTPS resolution every time it is given an XRI. That means XRI users never have to type https:// or do anything special at all to always have the benefit of a secure identifier. I should be able to type =drummond into any OpenID RP and have it always use HTTPS to resolve it.
The second key trust feature is that XRI infrastructure has a fundamental solution to the OpenID recycling problem. (See this short ACM paper for a full explanation of this problem.)
Since XRI infrastructure supports synonyms (different identifiers that identify the same target resource), all XRI infrastructure rooted in the XRI registry services offered by XDI.org have the operational requirement to assign persistent i-numbers for every i-name registered (at any level) and to never reassign those i-numbers to another registrant. No recycling. For example, both my i-names =drummond and =drummond.reed have the i-number synonym =!F83.62B1.44F.2813. That’s will always be my OpenID claimed identifier to any RP where I sign in as either =drummond or =drummond.reed. It will never be reassigned even if I let both those i-names lapse.
Unlike the URL hash solution to persistent identifiers in OpenID, the XRI solution has the advantage of being fully portable. Even if I let my i-names lapse, I still have full control of my i-number =!F83.62B1.44F.2813 forever.
For example, I can transfer it to any i-broker just like you can transfer a domain name to any domain name registrar. The “elephant in the living room” of the URL hash solution to OpenID recycling is that a hash like https://i-own-this-domain.com#1234 is absolutely worthless if i-own-this-domain.com is reassigned to a new registrant (which, as we know, can happen with a DNS name for all kinds of reasons, not all of which a registrant can control). Now the new registrant totally controls the whole URL hash space! Your “secure” OpenID identifier has been completely compromised.
So the truth is that the hash URL solution only works for very large providers where you can be reasonably sure that for example http://yahoo.com or http://aol.com is not going to sell out to someone that’s going to start reassigning yahoo.com or aol.com hash URLs. But for all the smaller providers – and mostly for all the individuals that would like to have their OpenID URL based on their own domain name – it doesn’t work at all.
—-
Lastly, besides the links above, another site I recommend for more info on XRI is Markus Sabadello’s @freexri site. Markus is one of the lead developers of the OpenXRI project (a Java implementation of XRI resolver/authority server/proxy server).


 Click
on the thumbnail image to the left and you will see in more detail what
Hillis envisions. That is, a database represented as a labeled graph,
where data objects are connected by labeled links to each other and to
concept nodes. For example, a concept node for a particular category
contains two subcategories that are linked via labeled links
"belongs-to" and "related-to" with text and picture. An entity
comprises another concept that is linked via labeled links "refers-to,"
"picture-of," "associated-with," and "describes" with Web page,
picture, audio clip, and data. For further information about this intellectual property - entitled Knowledge Web - see the blogged
entry US Patent App 20050086188: Knowledge Web (Hillis, Daniel W. et al).
Click
on the thumbnail image to the left and you will see in more detail what
Hillis envisions. That is, a database represented as a labeled graph,
where data objects are connected by labeled links to each other and to
concept nodes. For example, a concept node for a particular category
contains two subcategories that are linked via labeled links
"belongs-to" and "related-to" with text and picture. An entity
comprises another concept that is linked via labeled links "refers-to,"
"picture-of," "associated-with," and "describes" with Web page,
picture, audio clip, and data. For further information about this intellectual property - entitled Knowledge Web - see the blogged
entry US Patent App 20050086188: Knowledge Web (Hillis, Daniel W. et al).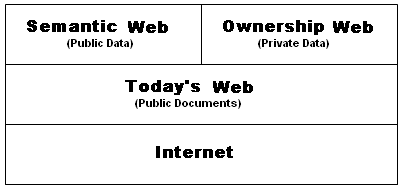
 Traditional monetary banks meet the expectations of real people and real businesses in the real world.
Traditional monetary banks meet the expectations of real people and real businesses in the real world. Where exactly is the sweet spot of data ownership?
Where exactly is the sweet spot of data ownership? Click
on the thumbnail to the left for the key architectural features for
such a data bank. They include a common registry of standardized data
elements, a registry of immutable informational objects, a
tracking/billing database and, of course, a membership database. This is the architecture for what may be called a Common Point Authoring™ system.
Again, where the definition of data ownership permits, users will host
their own 'accounts' within a data bank, and serve as their own
'network administrators'. What is made possible by this architectural
design is a distributed Cloud of systems (i.e., data banks). The
overall implementation would be based upon a massive number of user
interfaces (via API’s, web browsers, etc.) interacting via the Internet
between a large number of data banks overseeing their respective
enterprise-class, object-oriented database systems.
Click
on the thumbnail to the left for the key architectural features for
such a data bank. They include a common registry of standardized data
elements, a registry of immutable informational objects, a
tracking/billing database and, of course, a membership database. This is the architecture for what may be called a Common Point Authoring™ system.
Again, where the definition of data ownership permits, users will host
their own 'accounts' within a data bank, and serve as their own
'network administrators'. What is made possible by this architectural
design is a distributed Cloud of systems (i.e., data banks). The
overall implementation would be based upon a massive number of user
interfaces (via API’s, web browsers, etc.) interacting via the Internet
between a large number of data banks overseeing their respective
enterprise-class, object-oriented database systems. Click on the thumbnail to the right for an example of an informational object
and its contents as authored, registered, distributed and maintained
with data bank services. Each comprises a unique identifier that
designates the informational object, as well as one or more data
elements (including personal identification), each of which
itself is identified by a corresponding unique identifier. The
informational object will also contain other data, such as ontological
formatting data, permissions data, and metadata. The actual data
elements that are associated with a registered (and therefore immutable)
informational object would be typically stored in the Registered Data
Element Database (look back at 124 in the preceding thumbnail). That
is, the actual data elements and are linked via the use of pointers,
which comprise the data element unique identifiers or URIs. Granular portability is built in. For more information see the blogged entry US Patent 6,671,696: Informational object authoring and distribution system (Pardalis Inc.).
Click on the thumbnail to the right for an example of an informational object
and its contents as authored, registered, distributed and maintained
with data bank services. Each comprises a unique identifier that
designates the informational object, as well as one or more data
elements (including personal identification), each of which
itself is identified by a corresponding unique identifier. The
informational object will also contain other data, such as ontological
formatting data, permissions data, and metadata. The actual data
elements that are associated with a registered (and therefore immutable)
informational object would be typically stored in the Registered Data
Element Database (look back at 124 in the preceding thumbnail). That
is, the actual data elements and are linked via the use of pointers,
which comprise the data element unique identifiers or URIs. Granular portability is built in. For more information see the blogged entry US Patent 6,671,696: Informational object authoring and distribution system (Pardalis Inc.). "The
concept of data collection is knocking on the door of the beef
industry, but the concept is not registering. In fact, there actually
is a fairly large disconnect.
"The
concept of data collection is knocking on the door of the beef
industry, but the concept is not registering. In fact, there actually
is a fairly large disconnect. Steve Holcombe
Steve Holcombe














