As enterprise supply chains and consumer demand chains have beome globalized, they continue to inefficiently share information “one-up/one-down”. Profound "bullwhip effects" in the chains cause managers to scramble with inventory shortages and consumers attempting to understand product recalls, especially food safety recalls. Add to this the increasing usage of personal mobile devices by managers and consumers seeking real-time information about products, materials and ingredient sources. The popularity of mobile devices with consumers is inexorably tugging at enterprise IT departments to shifting to apps and services. But both consumer and enterprise data is a proprietary asset that must be selectively shared to be efficiently shared.
About Steve Holcombe
Unless otherwise noted, all content on this company blog site is authored by Steve Holcombe as President & CEO of Pardalis, Inc. More profile information:
Follow @WholeChainCom™ at each of its online locations:
The Internet is achieved via layered protocols. Transmitted data, flowing through these layers are enriched with metadata necessary for the correct interpretation of the data presented to users of the Web. Tim Berners-Lee, inventor of the Web says, “The Web was originally conceived as a tool for researchers who trusted one another implicitly …. We have been living with the consequences ever since ….” “[We need] to provide Web users with better ways of determining whether material on a site can be trusted ….”
Our lives have nonetheless become better as a result of Web service providers like Google and Facebook. Consumers are now conditioned to believe that they can – or should be able to - search and find information about anything, anytime. But the service providers dictate their quality of service in a one-way conversation that exploits the advantages of the Web as it exists. What may be considered trustworthy content is limited to that which is dictated by the service providers. The result is that consumers cannot find real-time, trustworthy information about much of anything.
Despite all the work in academic research there is still no industry solution that fully supports the sharing of proprietary supply chain product information between “data silos”. Industry remains in the throes of one-up/one down information sharing when what is needed is real-time “whole chain” interoperability. The Web needs to provide two-way, real-time interoperability in the content provided by information producers. Immutable objects have heretofore been traditionally used to provide more efficient data communications between networked machines, but not between information producers. Now researchers are innovatively coming up with new ways of using immutable objects in interoperable, two-way communications between information content providers.
Pardalis’ protocols for immutable informational objects make possible a value chain of two-way, interoperable sharing that makes information more available, trustworthy, and traceable. This, in turn, incentivizes increases in the quality and availability of new information leading to new business models.
Pardalis’ intellectual properties may be strategically compared to Van Jacobson’s impressive research at Xerox PARC (see the CCNx Project) that began in just the last few years. Jacobson's long-range goal is to adjust the architecture of the Internet with immutable named data. Pardalis' IP is focused on sooner commercialization opportunities for changing the Web with immutable, granular named information. But like Jacobson, we view the application of named immutable objects as an absolute prerequisite to authentication in a new world order providing more options for user-centric information sharing.
Update on Friday, April 22, 2011 at 10:14PM by
Steve Holcombe
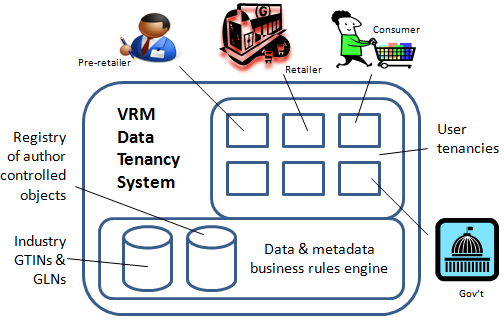
Assume that a retailer, a class of beef product pre-retailers (i.e., wholesalers, processors and vertically integrated operators), and a class of consumers are all multi-tenant members of a centralized personal data store for sharing supply chain information.
I gave an example of a multi-tenant Food Recall Data Bank in an earlier blog entitled Consortium seeks to holistically address food recalls. At the time I wrote this earlier blog I vacillated between calling it what I did, or calling it a VRM Data Bank. I refrained from calling it the latter because while the technology application is potentially very good for consumers (i.e., food recalls tied to point of sale purchases) it still felt too much like it was rooted in the world of CRM. For more about the VRM versus CRM debate see The Bullwhip Effect.
Below is a technology application whereby supply chain tenants may register their CPA informational objects with permissions and other instructions for how those objects may be minimally accessed, used and further shared by and to other supply chain participants. What one then has is what may more appropriately be called a VRM Data Tenancy System (VRM DTS).
So what can one do with this architecture? How can it get started in the marketplace of solutions? A reasonable beginning point is with real-time, supply chain test marketing of new food product lines. And by supply chain test marketing, I mean something clearly more than just consumer test marketing. What I am describing below is multi-directional, feedback loop for:
test marketing a new consumer product line for the purpose of driving retail sales, and
concurrently generating procurement and wholesale interest and support from pre-retailers.
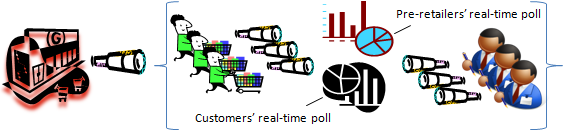
Assume that a retailer has been receiving word of mouth consumer interest in a particular beef product class (e.g., "ethically raised" beef products). Assume that pre-retailers have heretofore not been all that interested in raising, processing or purchasing "ethically raised" meat products for wholesale.
An initial "test market" object is authored and registered by the retailer for polling consumer interest via asynchronous authoring by individual consumers of their store outlet preferences, likely beef product quantity purchases of the new product line per week, etc. This object is revealed to a consumer class via their tenancies in the VRM DTS. The object is concurrently revealed to a class of pre-retailers via their tenancies, too. Each consumer is anonymous to the other consumers, and anonymous to the pre-retailers. Each pre-retailer is anonymous to the other pre-retailers, and anonymous to the consumers. But each consumer, as is each pre-retailer, is nonetheless privy to the consumers' real-time poll and the pre-retailers' real-time poll. The retailer watches all, being privy to the actual identities of both consumers and pre-retailers, while at the same time the retailer’s customer and pre-retailer client lists remain anonymous.
With this kind of real-time sharing of information, one can begin to imagine a competitive atmosphere arising among the pre-retailers. Furthermore, there is no reason the retailer's object could be further authored by the retailer to solicit real-time offers from the pre-retailers to procure X quantities of the beef products for delivery to identified outlets of the retailer by dates certain, in the same specific beef product class, etc. And there's no reason the "test market" object could not be further used to finalize a procurement contract with one or more pre-retailers ...
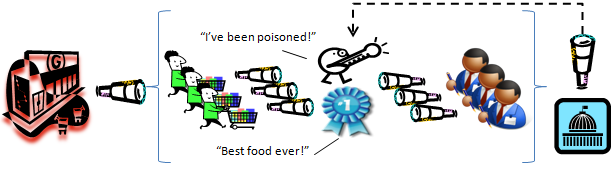
... which at the moment of execution shares real-time, anonymized information over to consumers as to dates of delivery of X quantity of beef products at identified retail outlets.
The "test market" object could be further designed for the consumer class to asynchronously provide real-time feed-back to the retailer regarding their experiences with the purchased product, and to perhaps do so even back to the pre-retailers based upon GLNs and GTINs. Depending on the retailer's initial design of the "test market" object, this consumer feedback to pre-retailers may be anonymous or may specifically identify a branded product. And, because food safety regulators are seeking "whole chain" traceability solutions, the government can be well apprised with minimal but real-time disclosures.
The dynamic business model for employing a VRM DTS includes greater supply chain transparency (increased, ironically, with consumer and pre-retailer anonymity), food discount incentives, real-time visualizations, new data available for data mining, and new product outlets for pre-retailers who have not previously provided products to the retailer. Perhaps most significantly there is the identification by the retailer of best of breed pre-retailers and loyal, committed consumers via an “auction house” atmosphere ...
... created from the sharing of real-time, sometimes anonymous information, between and among the pre-retailers and consumers.
Update on Thursday, November 21, 2013 at 8:31AM by
Steve Holcombe
The following was published by Nate Anderson for ARS Technica on 28 July 2009:
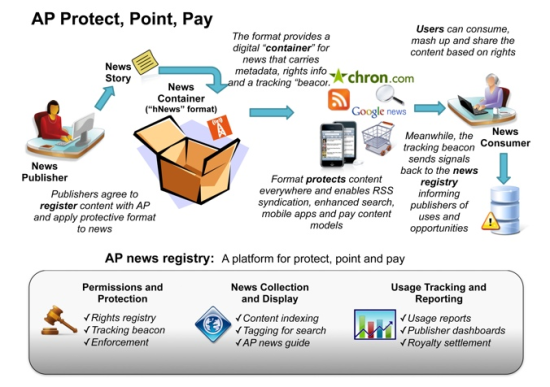
The Associated Press last week rolled out its brave new plan to "apply protective format to news." The AP's news registry will "tag and track all AP content online to assure compliance with terms of use," and it will provide a "platform for protect, point, and pay." That's a lot of "p"-prefaced jargon, but it boils down to a sort of DRM for news—"enforcement," in AP-speak.
My brother, Scot, and I traveled to North Dakota last week for meetings in Dickinson, N.D. (in southwest North Dakota) and Fargo, N.D. (southeastern North Dakota on the border with sister city, Moorhead, MN). Leaving Oklahoma we traveled north through Kansas, spent the night in North Platte, Nebraska. The next day took us by the Black Hills of South Dakota and Mt. Rushmore. If you have never been there, it's definitely worth the stop. I hadn't realized that the four President's gazed out of the Black Hills toward the east and a vast sea of prairie. We also drove on some beautiful, shoulderless 'blue' highways like that of Highway 85 between Belle Fourche, S.D. and Belfield, N.D. If you love the movie Dances with Wolves, you'll love this stretch of scenery. Lots and lots of pronghorn antelope, too. And Redig, S.D. really is one of those 'towns' with one house sitting on a rail straight road stretching endlessly into the distance. No kidding.
But, I digress.
For those of you who think you are unfamiliar with complex supply chains, allow me to jog your memory because you actually know more than you think you do. Spinach. Lead painted toys. Mad cows. Tomatoes. Jalapeno peppers. Hamburger. What do they all have in common? They are products that originate at the frayed ends of lengthy (even international) supply chains beset by many, many fears related to information sharing. And they are products that have been deemed poisonous (lead paint) or unhealthy (contaminated with e. coli, the prions that apparently cause BSE, or salmonella). Actually, the tomato industry got hammered this summer and they weren't even at fault. But take a look at some of the wonderful, free advertising the tomato industry received before the FDA called off the dogs.
What is the value of immediately accessible, credible, supply chain information? If it incontrovertibly points to you and your business as the culprit in a food disease crisis, for instance, then, yes, you are limiting your options. But if your company uses best practices in its crop management and limits its risks in advance, the value of credible information at your fingertips in a disease crisis is to immediately distinguish your company from (a) the actual culprits, and (b) all other companies who perform best crop management practices just like you but can't provide credible information for months. In fact the damage is not measured in months but in hours. Unfortunately, within hours the damage to reputation has been seeded into the minds of wholesale buyers and retail consumers. And without your ability to immediately provide exonerating information, the government regulators are going to 'play it safe' and cast a broad net that unfortunately ropes in a lot of innocent parties.
Information is like a sword. Unfortunately, if you don't firmly grab the sword and make it cut for you, in a crisis the sword will be out of your hands and you will potentially be sliced to death in the name of 'public health'.
The Dickinson Research Extension Center of North Dakota State University (NDSU DREC) is the first land grant extension center, and perhaps still the only one, to operate a beef livestock age and source verification program sanctioned by the USDA. It's called the CalfAID USDA PVP (i.e., process verified program employing RFID ear tags) and it's managed by NDSU DREC for the real cattlemen of the North Dakota Beef Cattle Improvement Association. The Agro-Security Resource Center at Dickinson State University also makes a significant contribution. It's partly research driven (with Congressional funding) and partly market-driven. It's market-driven in that those real livestock producers pay a fee per animal out of their pockets with the expectation that they will receive greater dollars (i.e., premiums) later on that the market pays for credible information about those calves. The CalfAID PVP exists to keep the calves connected with their age (i.e., birthdate) and source (i.e., origin) as each calf winds its way along an otherwise 'information dysfunctional' supply chain.
How dysfunctional is the information sharing? The U.S. has a national herd of about 100 million cattle. There's about a million cattle operations of one sort or the other. The vast majority of calf producers don't know where their calves eventually end up being slaughtered. Most packers don't know from what ranch or farm the animals they slaughter originated from. It's pretty much the same as it was in the 19th century. Most products (i.e., the livestock) are pushed one-step at a time as 'as is' commodities along a supply chain in which each segment only sees one step back, and one step forward. It's kind of like standing in a bucket line helping to pass along that bucket of water to put out a fire. You know who is passing you the bucket, and you know to whom you are passing it on. But in the beef industry, chances are you don't know where the fire is or even where the water is coming from.
In order to set the stage for scaling out from tracking thousands of cattle to tracking potentially hundreds of thousands or even millions of cattle, NDSU DREC has adopted a web service for their supply chain that empowers livestock producers to do with their cattle data what the following jazzy video envisions for social networks.
The web service, patented and engineered by Pardalis, is called a 'data bank' and it's coded in .NET with SQL server architecture on the back-end (though I would be very interested to see an open source, adjacent Linux system similarly funded and architected from Pardalis' IP as a data bank for the social networking space).
Common Point Authoring ModelSo how exactly does the 'data bank' work. To the right is the information model for the Common Point Authoring system (CPA) - that's the name that Pardalis has used in its most recent patents. You can also compare this image with other views, images and information about the CPA system to be found elsewhere in this blog site. Within the CPA system data cannot be changed once set (i.e., registered) so that the data can be used for verification and certification. Or, put another way, Pardalis has transformed the traditional application of immutable objects beyond run-time efficiencies, and empowered end-users with tools for granularly authoring, registering, controlling, and sharing these immutable objects.
The end-users 'own' and directly control sharing rights over what they author and register (or automatically collect and register), they just can't change it once it's authored. It becomes a part of a permanent, trustworthy record of the bank albeit controlled by the author. Other data bank account holders who receive any information from another data bank account holder know that. And they can remix it with their own data, and further share it, permission being granted to do so by the original author. This all helps build confidence, data credibility and, especially, trusted communication where it did not exist before. It provides a means for supply chain participants to reap benefits not just from their traditional products, but now also from their informational products. And, yes, there's no free lunch. The government might very well be able to subpoena those electronic records in their quest to protect the public's health. But they do the same with traditional monetary banks, too, don't they?
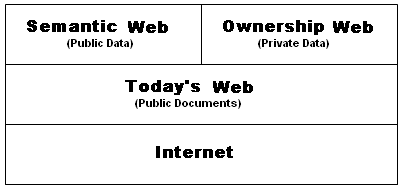
Now there are a number of technological ways to accomplish the same thing, it's just that Pardalis' object oriented approach provides certain long term advantages in terms of scalability, efficiency and granularity in 'the Cloud' that match up extremely well to an emerging Semantic Web. And you don't have to take my word for it. See, for example, the blogged entries, Efficient monitoring of objects in object-oriented database system which interacts cooperatively with client programs and Advantages of object oriented databases over relational databases. And Pardalis’ granular information banking system provides a substantial head-start in the race toward the standardization of a metadata platform for what I call an Ownership Web.
Online encyclopedias like Metaweb's Freebase Parallax are beginning to roll out tools for semantic search and semantic visualizations of publicly accessible information. See the nifty video clip in Freebase Parallax and the Ownership Web. Others like Google, Yahoo! , and Wikipedia will follow. The intrinsic value for connecting these search engines and encyclopedias with the Ownership Web will be the opportunity to likewise empower their authenticated end-users with the same semantic tools for accessing information that people consider to be their identity, that participants to complex supply chains consider to be confidential, and that governments classify as secret.
But, again, I digress.
Here's a film clip demonstrating the the authoring and portability of immutable data objects along the beef livestock supply chain. The interface is neither sexy nor jazzy. But it is effective. This type of look and feel makes sense for the beef livestock supply chain as Microsoft Excel is familiar to a large percentage of cattle producers (at least the ones who have moved on from pencil and paper). Currently, there's no audio because, frankly, I've provided the audio 'live' when called upon to do so. If you, too, would like a verbal walk through, drop me an e-mail. Or, in the alternative, I've scripted a written walk-through that you can download, print and follow as the clip runs its course. If you want to see a full screen version, click on the hyperlinked text below the graphic to take you to the Vimeo website.
In the coming months the data bank will be used not just to track the data uploaded and ported by CalfAID members, but also for helping to keep data connected with the animals from other age and source programs, and probably even for COOL compliance, too.
Once again, there's way more to the data bank than its application to the beef industry. As Dr. Kris Ringwall, Director of NDSU DREC, said in Fargo to a large vegetable growing company during a live demonstration of the data bank, "whether it's an animal or a vegetable, it's a product with a pedigree".
Well, that may be more of a paraphrase than a quote, but I know that Kris in this Presidential campaign season would nonetheless 'approve this message'.
Update on Thursday, June 3, 2010 at 11:28PM by
Steve Holcombe
The activities in North Dakota with CalfAID have been suspended. The livestock industry is struggling to find its way when it comes to animal identification. See the New York Times article dated 5 February 2009 USDA Will Drop Program to Trace Livestock in which USDA Secretary Vilsack announces the termination of the National Animal Identification System.
But the activities in North Dakota have by no means gone to waste.
In November, 2009 Pardalis joined with North Dakota State University, Oklahoma State University, Michigan State University, and Top 10 Produce LLC in a grant application filed in January for a Specialty Crops Research Initiative Coordinated Agricultural Project under USDA-NIFA-SCRI-002672. The essential premise of the $5M/5YR SCRI application was that providing supply chain participants (including consumers) with more control (i.e., traceability) over their data will increase the availability and quality of product data, and open up new, sustainable business models for both large and small companies. Though we received notice on 1 June 2010 that we would not be funded, here's what one reviewer had to say:
"Although [the application] addresses a topic area clearly of importance to Homeland Security, the FDA, and of course to USDA, the proposed traceability-system project, as written, could be used just as well for widgets as for fresh produce .... [But what] funding program within USDA or between the interested federal agencies mentioned above could be a better home for this proposal?
The "widgets remark" was right on target. We were indeed attempting to get across in our application that there is now an increasing critical need for bringing infrastructure standardization and uniformity to agricultural traceability in general, and not just for specialty crops supply chains.
Undeterred, the 'SCRI team' is committed to a process of filing applications, and two letters of intent have been filed under the Agricultural and Food Research Initiative, CFDA No. 10.310. They are entitled Stakeholder driven food supply safety system for a real-time detection, risk assessment, and mitigation of food borne contamination (Program Area Code: A4121 of the AFRI Food Safety RFA) and Stakeholder driven food supply safety system for a real-time detection, risk assessment, and mitigation of Shiga toxin-producing Escherichia coli in beef products (Program Area: A4101 of the AFRI Food Safety RFA). Funding for each is potentially up to $25M/5YRS.
And academics from additional universities are coming on board. So are new stakeholders in ag supply chains. The snowball is rolling faster down the hill. Getting bigger. Gaining momentum.
Update on Sunday, October 30, 2011 at 6:50PM by
Steve Holcombe
What’s right about the Semantic Web is that its most highly funded
visionaries have envisioned beyond a Web of documents to a ‘Data Web’.
Here's an example: a Web of scalably integrated data employing
object registries envisioned by Metaweb Technologies’ Danny Hillis and manifested in Freebase Parallax™, a competitive platform and application to both Google and Wikipedia.
AristotleMetaweb Technologies
is a San Francisco start-up developing and patenting
technology for a semantic ‘Knowledge Web’ marketed as Freebase Parallax.
Philosophically, Freebase Parallax is a substitute for a great tutor, like
Aristotle was for Alexander. Using Freebase Parallax users do not modify
existing web documents but instead annotate them. The annotations of Amazon.com
are the closest example but Freebase Parallax further links the annotations so
that the documents are more understandable and more findable. Annotations are also modifiable by their authors as better information becomes available to them.
Metaweb characterizes its service as an open, collaboratively-edited
database (like Wikipedia, the free encyclopedia) of cross-linked data
but, as you will see in the video below, it is really very much a next generation competitor to both Google and Wikipedia.
The Intellectual Property Behind Freebase Parallax
Click
on the thumbnail image to the left and you will see in more detail what
Hillis envisions. That is, a database represented as a labeled graph,
where data objects are connected by labeled links to each other and to
concept nodes. For example, a concept node for a particular category
contains two subcategories that are linked via labeled links
"belongs-to" and "related-to" with text and picture. An entity
comprises another concept that is linked via labeled links "refers-to,"
"picture-of," "associated-with," and "describes" with Web page,
picture, audio clip, and data. For further information about this intellectual property - entitled Knowledge Web - see the blogged
entry US Patent App 20050086188: Knowledge Web (Hillis, Daniel W. et al).
Freebase Parallax Incarnate
In the following video let's look at how this intellectual property for Knowledge Web is actually being engineered and applied by Metaweb Technologies in the form of Freebase Parallax.
You can hear it in the video. What Hillis and Metaweb Technologies well recognize is that as Freebase Parallax strives to become
the premier knowledge source for the Web, it will need access to new,
blue oceans of data. It
must find a gateway into the closely-held, confidential and classified
information that people consider to be their identity, that
participants to complex supply chains consider to be confidential, and
that governments classify as secret. That means that data ownership must be entered into the equation for the success of Freebase Parallax and the emerging Semantic Web in general.
Not
that Hillis hasn't thought about data ownership. He has. You can see it
in an interview conducted by his patent attorney and filed on December
21, 2001 in the provisional USPTO Patent Application 60/343,273:
Danny
Hillis: "Here's another idea that's super simple. I've never seen it
done. Maybe it's too simple. Let's go back to the terrorist version [of
Knowledge Web]. There's a particular problem in the terrorist version
that the information is, of course, highly classified .... Different
people have some different needs to know about it and so on. What would
be nice is if you ... asked for a piece of information. That you [want
access to an] annotation that you know exists .... Let's say I've got a
summary [of the annotation] that said, 'Osama bin Laden is traveling
to Italy.' I'd like to know how do you know that. That's classified.
Maybe I really have legitimate reasons for that. So what I'd like to
do, is if I follow a link that I know exists to a classified thing, I'd
like the same system that does that to automatically help me with the
process of getting the clearance to access that material." [emphasis added]
What Hillis was tapping into just a few months after 9/11 is just as relevant to today's information sharing needs.
But
bouncing around ideas about how we need data ownership is not the same
as developing methods or designs to solve it. What Hillis
non-provisionally filed, subsequent to his provisional application, was
the Knowledge Web application. Because of its emphasis
upon the statistical reliability of annotations, Knowledge web's IP is tailored made for the Semantic Web. But it is not designed for data ownership.
The Ownership Web
For the Semantic Web to reach its full potential, it
must have access to more than just publicly available data sources. Only with the empowerment of
technological data ownership in the hands of people, businesses, and
governments will the Semantic Web make contact with a horizon of new,
‘blue ocean’ data.
Conceptually, the Ownership Web would be
separate from the Semantic Web, though semantically connected as layer
of distributed, enterprise-class web platforms residing in the Cloud.
The
Ownership Web would contain diverse registries of uniquely identified
data elements for the direct authoring, and further registration, of
uniquely identified data objects. Using these platforms people,
businesses and governments would directly host the authoring, publication, sharing, control and tracking of the movement of their data objects.
The
technological construct best suited for the dynamic of networked
efficiency, scalability, granularity and trustworthy ownership is the
data object in the form of an immutable, granularly identified,
‘informational’ object.
A marketing construct well
suited to relying upon the trustworthiness of immutable, informational
objects would be the 'data bank'.
Data Banking
Traditional monetary banks meet the expectations of real people and real businesses in the real world.
People are comfortable and familiar with monetary banks. That’s a good thing because without people willingly depositing their money into banks, there would be no banking system as we know it.
By comparison, we live in a world that is at once awash in on-demand
information courtesy of the Internet, and at the same time the Internet
is strangely impotent when it comes to information ownership.
In
many respects the Internet is like the Wild West because there is no
information web similar to our monetary banking system. No similar
integrated system exists for precisely and efficiently delivering our
medical records to a new physician, or for providing access to a health
history of the specific animal slaughtered for that purchased steak.
Nothing out there compares with how the banking system facilitates
gasoline purchases.
If an analogy to the Wild West is apropos,
then it is interesting to reflect upon the history of a bank like Wells
Fargo, formed in 1852 in response to the California gold rush. Wells
Fargo wasn’t just a monetary bank, it was also an express delivery
company of its time for transporting gold, mail and valuables across
the Wild West. While we are now accustomed to next morning, overnight
delivery between the coasts, Wells Fargo captured the imagination of
the nation by connecting San Francisco and the East coast with its Pony
Express.As further described in Banking on Granular Information Ownership, today’s Web needs data banks that do for the on-going gold rush on information what Wells Fargo did for the Forty-niners.
Banks
meet the expectations of their customers by providing them with
security, yes, but also credibility, compensation, control,
convenience, integration and verification. It is the dynamic,
transactional combination of these that instills in customers the
confidence that they continue to own their money even while it is in
the hands of a third-party bank.
A data bank must do no less.
Ownership Web: What's Philosophically Needed
Where exactly is the sweet spot of data ownership?
In
truth, it will probably vary depending upon what kind of data bank we
are talking about. Data ownership will be one thing for personal health
records, another for product supply chains, and yet another for
government classified information. And that's just for starters because
there will no doubt be niches within niches, each with their own
interpretation of data ownership. But the philosophical essence of the
Ownership Web that will cut across all of these data banks will be this:
That information must be treated either or both as a tangible, commercial product or banked, traceable money.
The
trustworthiness of information is crucial. Users will not be drawn to
data banks if the information they author, store, publish and access
can be modified. That means that even the authors themselves must be
proscribed from modifying their information once registered with the
data bank. Their information must take on the immutable characteristic
of tangible, traceable property. While the Semantic Web is about the
statistical reliability of data, the Ownership Web is about the
reliability of data, period.
Ownership Web: What's Technologically Needed
What
is technologically required is a flexible, integrated architectural
framework for information object authoring and distribution. One that
easily adjusts to the definition of data ownership as it is variously
defined by the data banks serving each social network, information
supply chain, and product supply chain. Users will interface with one
or more ‘data banks’ employing this architectural framework. But the
lowest common denominator will be the trusted, immutable informational objects
that are authored and, where the definition of data ownership permits,
controllable and traceable by each data owner one-step, two-steps,
three-steps, etc. after the initial share.
Click
on the thumbnail to the left for the key architectural features for
such a data bank. They include a common registry of standardized data
elements, a registry of immutable informational objects, a
tracking/billing database and, of course, a membership database. This is the architecture for what may be called a Common Point Authoring™ system.
Again, where the definition of data ownership permits, users will host
their own 'accounts' within a data bank, and serve as their own
'network administrators'. What is made possible by this architectural
design is a distributed Cloud of systems (i.e., data banks). The
overall implementation would be based upon a massive number of user
interfaces (via API’s, web browsers, etc.) interacting via the Internet
between a large number of data banks overseeing their respective
enterprise-class, object-oriented database systems.
Click on the thumbnail to the right for an example of an informational object
and its contents as authored, registered, distributed and maintained
with data bank services. Each comprises a unique identifier that
designates the informational object, as well as one or more data
elements (including personal identification), each of which
itself is identified by a corresponding unique identifier. The
informational object will also contain other data, such as ontological
formatting data, permissions data, and metadata. The actual data
elements that are associated with a registered (and therefore immutable)
informational object would be typically stored in the Registered Data
Element Database (look back at 124 in the preceding thumbnail). That
is, the actual data elements and are linked via the use of pointers,
which comprise the data element unique identifiers or URIs. Granular portability is built in. For more information see the blogged entry US Patent 6,671,696: Informational object authoring and distribution system (Pardalis Inc.).
The Beginning of the Ownership Web
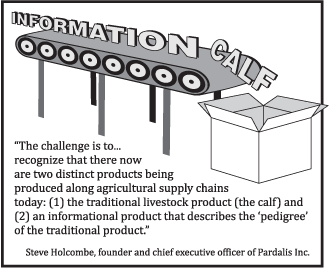
Common Point Authoring is going live this fall in the form of a data bank for cattle producers in the upper plains. Why the livestock industry? Because well-followed commentators like Dr. Kris Ringwall, Director of the Dickinson Research Extension Center for North Dakota State University, recognize that there are now two distinct products being produced along our nation's complex agricultural supply chains: (1) a traditional product, and (2) an informational product describing the pedigree of the traditional product.
"The
concept of data collection is knocking on the door of the beef
industry, but the concept is not registering. In fact, there actually
is a fairly large disconnect.
This
is ironic because most, if not all, beef producers pride themselves on
their understanding of the skills needed to master the production of
beef. Today, there is another player simply called “data.”
The
information associated with individual cattle is critical. Producers
need to understand how livestock production is viewed ....
That
distinction is not being made and the ramifications are lost revenue in
the actual value of the calf and lost future opportunity. This is
critical for the future of the beef business ...."
Ownership Web: Where It Will Begin
The Ownership Web will begin along complex product and service supply chains where information must be trustworthy, period. Statistical reliability is not enough. And, as I mentioned above, the Ownership Web will begin this fall along an agricultural supply chain which is among the most challenging of supply
chains when it comes to information ownership. Stay tuned as the planks of the
Ownership Web are nailed into place, one by one.

 Steve Holcombe
Steve Holcombe